AI 典範轉移 Ep.1:自我演化的監控Skill
為 post-release 監控建了一個 AI skill,結果改變了我對整個軟體開發生命週期的想法。

我帶 Ubiquiti 的 SSO 團隊。我們負責認證、token 管理、使用者 provisioning——那種每個團隊都依賴但沒人想到的基礎設施,直到它壞掉。這是一份沒人感謝但出了事一定被抓出來的工作。
幾週前我們在 email module 裡發現了瓶頸。每個碰到 email 的 API——密碼重設、MFA 驗證、邀請流程、通知偏好——都比應有的速度慢。修法很直接:把 email module 每次呼叫都重新初始化的關鍵元件做 cache。Template rendering、SMTP 連線 metadata、收件人驗證結果。那些在 request 之間不會變但每次都從頭建立的東西,就像一個每天清 node_modules 以求心靈淨化的工程師一樣。
我們對 caching layer 的正確性有信心。Unit test 過了。Integration test 也過了。問題是:真實流量打上去會怎樣?每個 import email module 的 API 應該都會變快。「應該」大概是工程師詞彙表裡最危險的兩個字。
是時候監控這次 rollout 了。
舊的做法,或:為什麼我花了兩天建一個沒人看的 Dashboard
這事我做過很多次了,劇本永遠一樣。
首先,你坐下來列舉每一個可能受影響的 API。你打開 codebase,grep email module 的 import,建一份清單。你漏了兩個,因為它們走的是一個不直接 import module 的內部 wrapper。你之後會發現這件事,在最糟糕的時機。
然後你寫一個 script。或者你建一個 CloudWatch dashboard。或者兩個都做——因為 script 給你原始數據,dashboard 給你漂亮的圖表,好在有人在 incident channel 問「一切都還好嗎?」的時候回覆一些比「ok」更有說服力的東西。
Dashboard 上有每個 API 的 status code 分布、p50 和 p95 latency、request volume 的面板。你把它們排列整齊。你設定合理的 Y 軸範圍。你暫時覺得自己很能幹。
你部署了。
第一個小時看起來不錯。Latency 全面下降。你在 team channel 發了一張截圖和一個低調的慶祝 emoji。然後有人回報那個 legacy user-export endpoint——兩個季度前就 deprecated 了但三個企業客戶還在呼叫因為沒人強制執行 deprecation 的那個——開始回 500。原來 caching layer 跟一段會把 mutable config object 傳進 email module 然後期待 module 修改它作為 side effect 的 code path 互動不良。那種你永遠不會刻意設計但在任何超過十八個月的 codebase 裡自然長出來的東西。
現在你進入 incident 模式。你需要一個不在 dashboard 上的 API 的數據。你 SSH 進一台機器。你對 metrics store 跑 ad-hoc query。你用 grep 的輸出和善意建構一個 mental model。你找到 bug,推一個修復,驗證修復,然後開始文書作業:incident report、deprecated endpoint migration 的 Jira ticket、一個 post-mortem action item 寫著「改善監控覆蓋率」。你還需要更新 dashboard 把你漏掉的 API 加進去,因為下一次——永遠有下一次——你想看到完整的畫面。
監控本來應該幫你度過 release 的。結果它變成了自己的專案,有自己的 bug、自己的維護負擔、自己的技術債。你建的 dashboard 截至今天是正確的。到了下一季,當有人新增一個依賴 email 的 endpoint,它又會不完整,而且沒人會更新它,因為沒人會更新 dashboard。它們是基礎設施的技術債:短命、繁殖力強、第一天之後基本上就被忽略了。
這個循環我經歷了十幾次。我以為事情就是這樣運作的。營運的代價。跟加班和 on-call 一樣,是工程師逃不掉的宿命。
新的做法,或:跟你的監控聊天
這次我做了不一樣的事。我沒有寫 script 或建 dashboard,而是請 Claude Code 幫我建一個 skill。
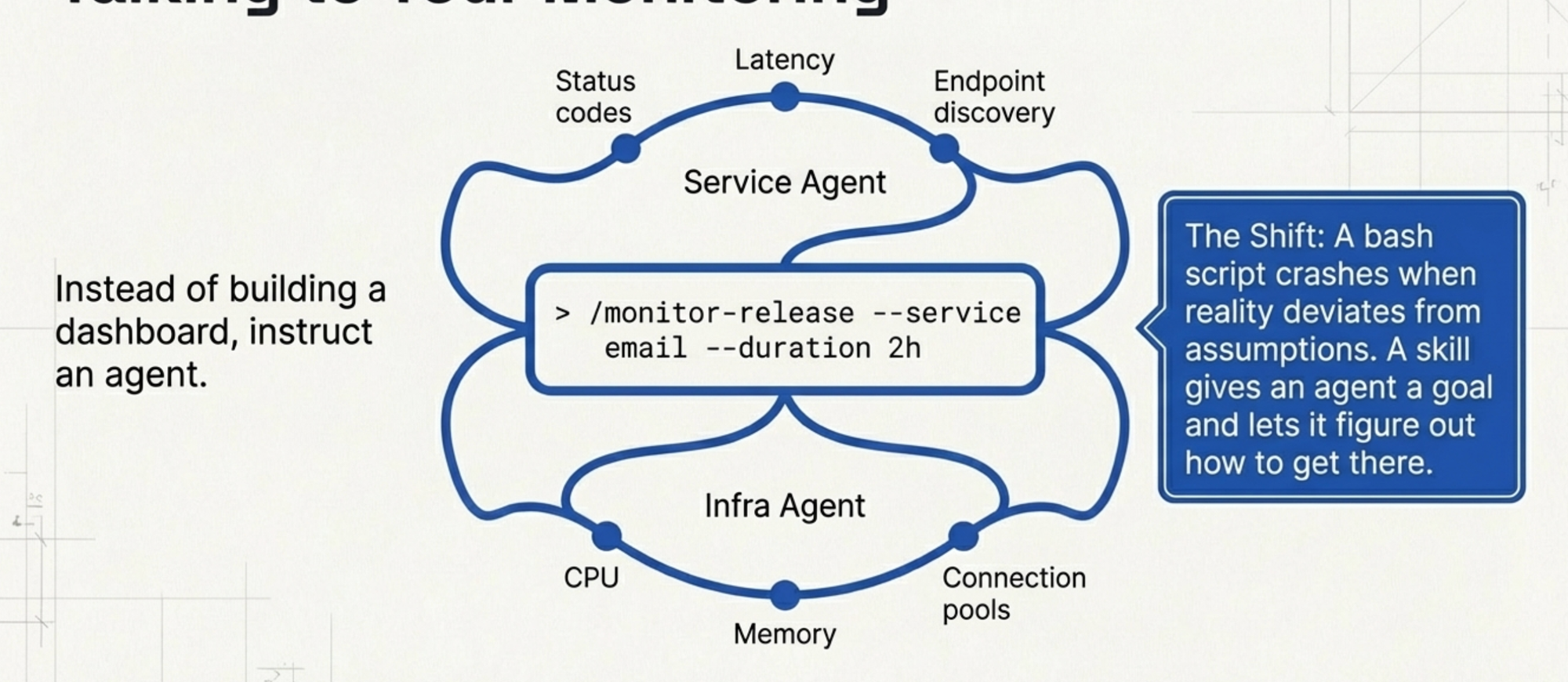
Skill 在 Claude Code 裡是一個可重複使用的 command——一組指令和 tool 定義的集合,agent 可以執行它。把它想成一個會思考的 script。Bash script 遵循一個固定的指令序列,當現實偏離作者的假設時就崩潰;skill 給 agent 一個目標,讓它自己想辦法達成。
大致上我是這樣要求的:「建一個 post-release 監控 skill。它應該 spawn 兩個並行的 agent——一個看 service 層級的 metrics,像是每個 API endpoint 的 status code 和 latency;一個看基礎設施層級的 metrics,像是 CPU、記憶體和 connection pool 使用率。我要能告訴它監控多久、聚焦哪個服務。」
就這樣。不用手動列舉 API。不用設計 dashboard layout。不用寫 CloudWatch metric query。Skill 理解監控目標,知道怎麼查詢我們的 metrics 系統,而且是透過觀察實際流量數據來找出哪些 endpoint 存在,而不是靠我那不完整的 codebase mental model。
我們寫了一個 command:/monitor-release --service email --duration 2h。Agent 啟動,分叉成兩個監控執行緒,開始觀察。它在終端機給我即時摘要。Service agent 回報每個 endpoint 的 latency 變化和百分比改善。Infra agent 回報資源使用率趨勢。兩個都會標記異常。
我部署了 caching layer。Skill 開始工作。Latency 下降了。摘要看起來很乾淨。我把截圖發到 team channel。
然後那個 legacy user-export endpoint 開始噴 500。跟舊世界裡會碰到的一樣的 bug。一樣不在我雷達上的 deprecated API。
但這次,監控 agent 注意到了。它不受限於我 hardcode 在 dashboard 裡的預定義 endpoint 清單。它觀察的是 email service 的實際流量模式,當一個原本回 200 的 endpoint 突然開始回 500,它標記了。我不用 SSH 進任何機器。我不用寫 ad-hoc query。Agent 告訴我:「/v1/users/export endpoint 從 14:32 UTC 開始出現 500 status code 激增。這個 endpoint 不在初始監控範圍內,但它透過 UserBulkOperations 間接 import 了 email module。要我加進主要觀察清單嗎?」
要。當然要。
當你可以直接說出你想要什麼

舊的做法和新的做法在這裡分歧大到叫它「改進」都太保守了。這是不同的生命週期。
舊世界裡,發現你需要監控一個新 endpoint 意味著:到 CloudWatch,建一個新 widget,設定 metric query,選 statistic,設 period,調整 dashboard layout,儲存,回去處理你本來在調查的問題。最少十分鐘,前提是你很熟 CloudWatch。二十分鐘如果你需要查 metric namespace。
新世界裡:「把 /v1/users/export 加到觀察清單。」搞定。Agent 已經在監控了。花費時間:四秒鐘加上打一句話需要的卡路里。
但更好的還在後面。初始監控期之後,我意識到我需要更細緻的 latency 數據。預設是 p50 和 p95。對 caching 變更來說,我想看 p99——因為 cache miss 不成比例地影響 tail latency。我也想看最小值,因為可疑的低最小值可能代表某個 endpoint 在到達 email module 之前就 short-circuit 了。我還想看 p99 排除 outlier,因為我們有一些企業客戶的 request 因為資料量大所以合理地比較慢,它們會 skew tail。
舊世界:每個 endpoint 三個新的 CloudWatch math expression。一種 metric query 語言,讀起來像有人在收訊很差的電話裡跟一個 Perl 愛好者描述 SQL。最少三十分鐘。
新世界:「也給我看 p99、min、和排除 response time 前 1% 的 p99。」Agent 更新了自己的報告。下次刷新,新的欄位就在那了。
然後這是讓我到現在還驚訝的部分,即使已經這樣工作了好幾週:我叫 agent 更新 skill 本身。不只是當前的監控 session——而是 skill 的定義。「更新 skill,讓 p99、min 和 p99-excluding-outliers 預設就包含在未來的執行中。」Agent 修改了自己的指令。下次我團隊的任何人跑 /monitor-release,那些統計數據從一開始就在那裡。沒人需要去要求。沒人需要知道我曾經花了一個下午才發現它們很重要。Skill 吸收了這個教訓。
會自我學習的Skill
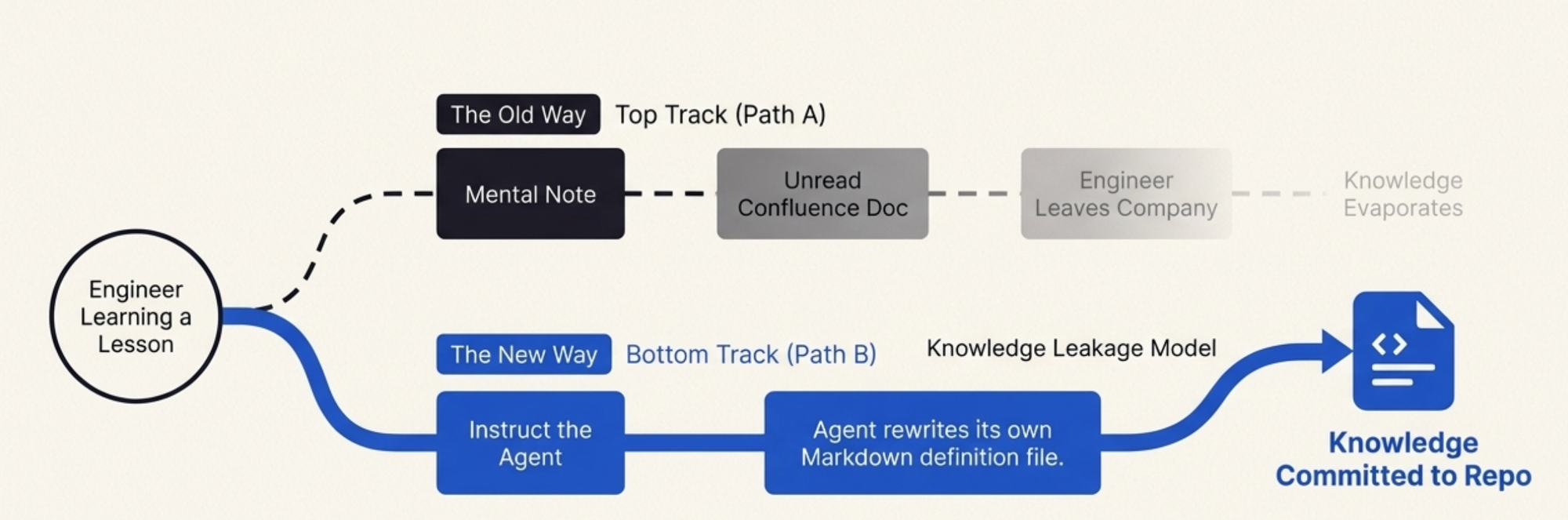
這是我一直在想的洞察:skill 不是用完就丟的東西。它是一個累積營運智慧的產出物。
一個監控 script,一旦寫完,就凍結了。它反映的是一個工程師在某個時間點的理解。當你在 release 過程中學到東西——這個 endpoint 重要、那個 metric 是雜訊、這個 threshold 太敏感——你可以更新 script,但老實說大部分人不會。他們在心裡記一下,下次手動處理,最終離開公司,帶走那些知識。Script 繼續凍結著。某個新人跑了它,拿到不完整的數據,循環重來。
Skill 有不同的生命週期。每次你使用它,你都可以教它。「嘿,也觀察 connection pool exhaustion——上次被這個咬到。」Agent 更新 skill。「部署期間 /v1/health 的 404 spike 可以忽略,那是預期的。」Agent 加入例外。Skill 變成團隊對於 release 期間什麼重要的集體記憶,編碼在一種既人類可讀又機器可執行的格式裡。
我們的 rollout 結束時——caching layer 驗證完成、bug 修復、deprecated endpoint 打了 patch、incident report 寫完——我把 skill commit 進 repository。它是一個 Markdown 檔案加上 tool 定義和監控指令。新工程師可以讀它,理解團隊在 performance release 期間監控什麼以及為什麼。他們也可以直接跑它,開箱即用地拿到監控,不用理解裡面每一個決策。
跟舊世界比一下。Release 結束後你有的是:一個已經半過期的 CloudWatch dashboard、一個只在你機器上能跑的 bash script、一份在 Confluence 裡沒人會讀的 incident report、還有散布在 Slack thread 裡的部落知識。新工程師加入,問「我們怎麼監控 release?」然後得到一個聳肩和一個兩季之前的 dashboard 連結。
現在他們拿到一個 skill。他們跑它。它能用。當他們在自己的 release 中學到新東西,他們教給 skill,下一個人就受益。
我現在真正相信的
我想在這裡謹慎一點,因為我在這個產業待得夠久,知道「現在一切都不同了」幾乎永遠是錯的,而那少數幾次它是對的,對的方式也是沒人預料到的。
AI skill 沒有取代監控。我還是有 CloudWatch。還是有 Grafana。Metrics 管線沒有變。變的是我和我的監控之間的介面——以及我在使用過程中累積的營運知識的生命週期。
這件事的影響超乎想像地大。
傳統的開發生命週期有這些離散的、痛苦的交接:你做計畫、建監控、部署、發現監控不完整、修監控、發現問題、修問題、再次更新監控、寫 incident report、開 ticket,然後你繼續前進,監控開始腐爛。每個階段是獨立的活動,有自己的工具和自己的摩擦。
Skill 把這一切壓縮成一個連續的對話。Release 前,你描述你想觀察什麼。Release 期間,你用說的即時調整。Release 後,你 commit skill,調整被保留下來。監控、incident 調查、知識捕獲——現在它們是同一個活動。你不用在「監控」和「incident response」和「文件撰寫」之間切換 context。你只是持續跟 agent 對話,skill 吸收一切。
這是典範轉移嗎?我不確定我在意那個標籤。我知道的是,這次 release 我花了大約兩小時在監控上,上一次沒有 skill 的同等規模 release,我花了將近兩天。我知道監控覆蓋率更好——skill 抓到了一個我會漏掉的 endpoint。我知道我 commit 的那個產出物對我的團隊比我建過的任何 dashboard 都有用。而且我知道下一次,skill 會比這次更好,因為它從這次 release 學到了東西,下一次它也會繼續學。
最好的工具是那些越用越聰明的工具。我的監控設定,職涯中第一次,符合這個標準。
不過 CloudWatch dashboard 我還是會留著。舊習難改,需要把累積重要的數據還是放上去,而且總得有人截圖給 incident channel 看。有些典範會轉移。有些只是多了一個更好的副駕駛。