AI Paradigm Shift Ep.2: The Triage Agent That Learned From Every Incident
How a read-only AI triage agent transformed our incident response from a one-hero show into a team sport.


Three weeks after I built the monitoring skill from Episode 1, our SSO service started acting up — specifically, passkey login on a new Android app that had just gone to market in beta. Not a full outage. The insidious kind of broken where most authentication methods work and one doesn't, so the bug reports trickle in slowly and you spend the first twenty minutes wondering if it is a real incident or just a beta-quality client doing beta-quality things.
It was real.
Passkey authentication was failing intermittently on the beta Android app. Brian built the WebAuthn flow eight months ago — I reviewed every PR but never did the hands-on staging testing, so my understanding was architectural, not visceral. Brian was on vacation in Hokkaido, unreachable in every way that matters. The root cause, as we would later discover, was on us: the beta client had been configured with the wrong passkey origin, and WebAuthn does not forgive origin mismatches.
This is the part of incident response nobody talks about in post-mortems: the knowledge bottleneck is not a process failure. It is a structural inevitability. Brian built the passkey feature. He knows which database tables it touches, which Athena queries reveal its failure modes, which CloudWatch metrics actually matter versus which ones look alarming but mean nothing. That knowledge lives in his head, accumulated over months of debugging sessions and late-night deploys. I know the architecture from code review, but knowing how something is designed and knowing how it breaks are two very different things. The gap between reviewing a PR and debugging a production incident is the gap between reading a map and navigating a city at night.
So here is what happens in the old world — briefly, because if you have ever been the person on the team who has to debug something they did not build, you already know. I open six browser tabs. I dig through Brian's old Athena queries in our shared workspace, trying to figure out which ones are still relevant. I read CloudWatch metrics I half-understand, pattern-matching against what I remember from code review. Steven, our designated incident liaison, watches my screen because he wants to learn, but I am too deep in query results to narrate what I am doing — partly because I am still figuring it out myself. The stakeholder update does not get sent. The liaison role is a polite fiction we maintain because the incident response template says we need one. The person trying to debug is too busy debugging to communicate, and the person who should communicate does not have enough context to say anything useful.
That is the structural problem. Vendor triage copilots exist — PagerDuty, Datadog, others — but they optimize for their own telemetry stack. Ours needed to reason across CloudWatch, application logs, deployment history, and domain-specific Athena queries simultaneously, in a way only a custom agent with full context of our stack could do. Everything that follows is an attempt to break the knowledge bottleneck with that agent.
The Fear Is Reasonable. The Boundary Is Simple.
The fear of letting AI touch infrastructure is not theoretical. Earlier this month, Amazon held a company-wide engineering meeting after a pattern of outages tied to AI-assisted code changes — including a six-hour shopping site outage on March 5th that knocked out checkout, login, and product pricing. Their internal briefing described "high blast radius" incidents linked to "Gen-AI assisted changes." Amazon's response was to require senior engineer sign-off on all AI-assisted production changes. The instinct everywhere is the same: AI near infrastructure is dangerous, so add friction.
I understand the caution. I have the same fear. The last thing I want during an active incident is an AI agent deciding to helpfully restart the database or modify a security group.
But Amazon's problem — and the instinct to add blanket friction — conflates two very different things. There is an enormous gap between reading a CloudWatch metric and modifying an Auto Scaling group. One is observation. The other is action. We do not refuse to let junior engineers look at production dashboards because we are afraid they might accidentally click "Terminate Instance."
The fix was a service account with read-only permissions. An IAM policy: CloudWatch GetMetricData, RDS Performance Insights reads, Athena queries against read-only analytics tables, ALB and WAF metric reads, CloudTrail lookups. No PutMetricAlarm. No ModifyDBInstance. Nothing that modifies state.
This turns out to be the only safety boundary that matters in practice. Not "can the AI access infrastructure" but "can the AI change infrastructure." Read-only access gives you an extra pair of eyes without giving you an extra pair of hands. I brought the policy back to the platform team, they audited it, added a few explicit denies, and agreed to a trial. The trial is still running. Nobody has asked me to stop.
Fourteen Minutes
The second incident arrived on a Tuesday. Passkey authentication failures again, this time concentrated on Android beta users in specific regions. I pasted the CloudWatch alarm payload, the first three bug reports from the beta channel, and the service name into the triage agent. One command: /triage-incident --context <paste>.
The agent spawned three parallel investigation threads — service-level metrics, infrastructure health, and passkey-specific queries — and reported back while I was still waiting for the RDS Performance Insights console to render. (The console takes a genuinely impressive amount of time, as if each pixel is hand-painted by an AWS intern.)
The infrastructure thread found it. Primary RDS read IOPS at 4x normal. Connection pool at 89%. The WebAuthnCredentialLookup query had gone from a P95 of 12ms to 340ms. The agent correlated this with a CloudTrail entry showing a compliance batch job — quarterly, full table scans on the same tables the passkey lookup uses — had started twenty minutes before the first beta user report.
Fourteen minutes from alert to root cause. I had not typed a single Athena query.
Here is what mattered more than the speed: I had nothing to do with my hands. The agent was investigating. My normal instinct — run queries, check dashboards, build a mental model — was already being done. So I did the thing that incident response frameworks have begged me to do for years. I communicated.
I spun up a second agent session connected to Atlassian. Incident report created, findings fed in as they arrived. When we confirmed the batch job was the cause, the compliance team got tagged within minutes instead of the usual "someone remembers to Slack them thirty minutes later." Steven was reading the triage output alongside me, following the diagnostic reasoning as structured narrative rather than trying to parse my frantic tab-switching. He started asking questions: "Why did it check DynamoDB latency separately from RDS?" Because the passkey flow hits both stores, and you need to isolate which layer is the bottleneck. He was learning the reasoning, not by watching me type too fast to follow, but by reading an investigation that explained itself.
Four stakeholder updates sent during the incident. In the old world, that number would have been zero.
Total time from alert to mitigation: twenty-two minutes. I started to feel like the tool was trustworthy. That feeling was about to be corrected.
When the Agent Was Wrong, and Why That Was the Point
The third incident, two weeks later, the agent got it wrong. Elevated 5xx on the token exchange endpoint. The agent confidently blamed DynamoDB GSI throttling — a metric spike that correlated perfectly with the error onset. I almost acted on it. But the GSI was at 40% of provisioned capacity. Nowhere near throttling. The agent had pattern-matched on "metric went up at the same time as errors" without asking whether the magnitude was enough to matter. The real cause was a rate limiter typo in that morning's deploy — 50 requests per second instead of 500. One missing zero, sitting in the deployment diff the agent never checked.
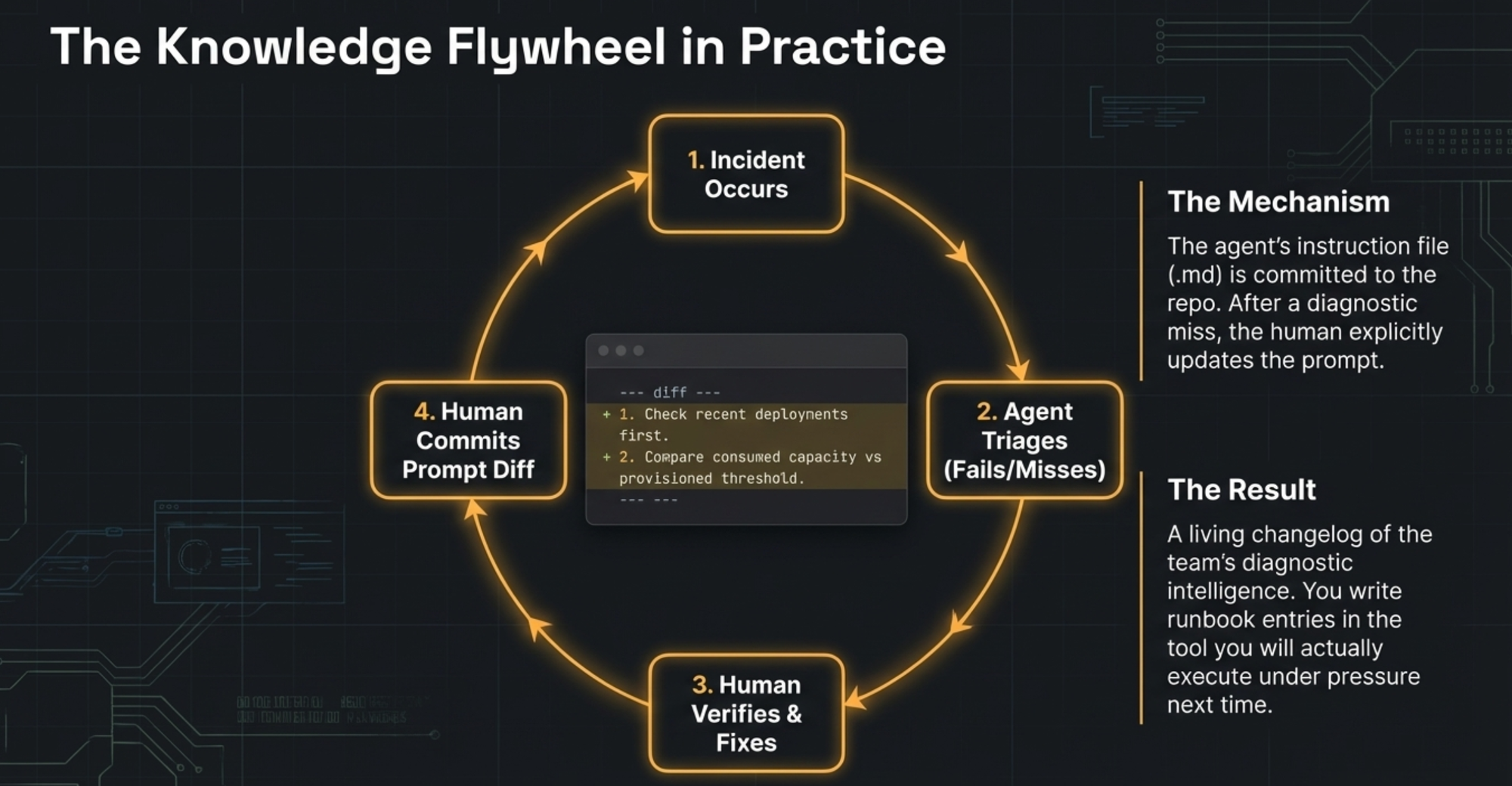
Eighteen minutes lost. Not catastrophic, but enough to change how we used the tool. We stopped treating the agent's output as a verdict and started treating it as a brief — hypotheses with evidence, reviewed by a human who asks: does the anomaly actually explain the impact? What changed recently? After the failure, I updated the skill to check deployment history first and to validate metric thresholds against provisioned capacity, not just look for spikes. Steven caught another gap in the fourth incident: no ECS deployment status check. He told me, I updated the skill.
The pattern became clear. Every time the agent was wrong or incomplete, I just told it: "You missed the deployment history. Update the triage skill so that checking recent changes is always the first investigation thread." The agent rewrote its own skill. Next time I told it: "When you check DynamoDB metrics, compare consumed capacity against provisioned capacity — a spike means nothing if you are at 40% of your limit." The agent updated itself again. Steven found the ECS gap, told me, and I relayed it the same way. One sentence, and the skill absorbed the lesson.

No manual editing of config files. No writing runbook entries after the fact. I just talked to the agent about what it got wrong, and it fixed its own playbook. The corrections accumulated. The skill got committed to the repo, and the diff tells the story: each change traces back to a specific incident and a specific mistake. It is a changelog of the team's diagnostic intelligence, maintained not by discipline but by the natural pressure of real incidents.
The Fifth Incident
By the fifth incident, those one-sentence corrections had compounded into something I did not expect. The skill checked deployment history first. It validated metric thresholds against provisioned capacity. It checked ECS deployment status. All lessons it learned from being told, once, what it missed. I barely intervened during the triage phase. The agent was not perfect — it still flagged irrelevant metrics occasionally, and its severity assessments ran a notch too high. But it was operating at the level of a teammate who had been on the team for a year, not the blank-slate tool it was on day one.
Steven used it solo last week. An alert fired for elevated 401 responses on the token refresh endpoint. He ran the triage skill. It checked recent deployments first (none), swept infrastructure metrics, then went narrow on the token validation subsystem. Twelve minutes to root cause — an upstream identity provider had changed their JWKS endpoint response format, breaking our key rotation. Steven filed the incident report, communicated with stakeholders, and coordinated the fix. He did not need me. He did not Slack me. I found out from the post-mortem document the next morning.
That is the moment I knew the structural problem was actually broken. Not dented, not mitigated. Broken. Steven ran an incident end-to-end using a skill that had learned from every previous mistake — mistakes I had simply talked it through, one sentence at a time.
What the Numbers Say

I want to be honest about measurement. We did not run a controlled experiment. We do not have clean before-and-after metrics because the "before" was not instrumented. What we have is timestamps from Slack messages, incident reports, and my own notes.
Before the triage agent, our median time from alert to root cause identification — across the six incidents I can reconstruct from 2025 — was roughly seventy minutes. The range was thirty minutes (for problems I had seen before and could diagnose from muscle memory) to four hours (for novel failure modes that required building understanding from scratch).
With the triage agent, across five incidents, the median is eighteen minutes. The range is twelve to twenty-eight. The twenty-eight-minute outlier was the third incident, where the agent was wrong and we lost time on a false lead.
The number I care about more: stakeholder updates sent during the active incident phase. Before: a median of one, usually sent after the fix was already in progress. After: a median of four, with the first one going out within ten minutes of the alert. That is the communication unlock. The triage agent did not just speed up diagnosis. It freed the humans to do the part of incident response that humans are actually good at and that actually matters to the people waiting for answers.
What the Engineer Should Have Been Doing All Along
The conventional accounting of incident cost focuses on downtime minutes. Those matter. But the hidden cost — the one that compounds quarter over quarter — is the knowledge monopoly. Every incident that only one person can triage makes that person more indispensable and the team more fragile. The experienced engineer becomes a single point of failure not because they want to be, but because incident work is inherently apprenticeship-based, and there are never enough incidents to train everyone, and the incidents that do occur are too urgent to use as teaching moments.
The triage agent did not replace me. It revealed what I should have been doing all along.
All those years of incident response, I thought my job was to diagnose the problem. To be the person who knew the queries, knew the metrics, knew the system's failure modes — or at least knew enough to muddle through when the person who really knew was unavailable. That was the expectation. But diagnosing the problem was never the hard part for the team — it was only the hard part because the knowledge was locked in one person's head, and that person was not always in the room. The actual hard part, the part that affected customers and stakeholders and the business, was communicating clearly under pressure, coordinating across teams, and making judgment calls about severity and mitigation trade-offs. I was not doing any of that because I was too busy being the human query engine.
The agent took over the query engine role. What remained was the work that actually mattered: talking to people, making decisions, and teaching others. It turns out that the "hero engineer" was not heroic. The hero engineer was a bottleneck who happened to type fast.

I do not know what the sixth incident will teach the skill. That is the point. The skill does not need to be complete on day one. It just needs to be better after each incident than it was before, and the team needs to trust it enough to use it and skeptical enough to correct it. So far, both of those bars have been easy to clear.