AI 典範轉移 Ep.2:從每次事故中學習的Triage Skill
診斷問題從來不是團隊的難處,難的是將鎖在腦袋裡的知識釋放出來。當 AI 接手了機械化的查詢工作,剩下的才是真正重要的工作:跟人講話、決策、以及傳承經驗。


[以下故事人名以及事件都為了保護隱私而有所虛構]
第一集的監控 skill 做好三週後,我們的 SSO 服務出了問題——具體來說,是一個剛上市 beta 版的 Android app 上的 passkey 登入。不是全面中斷,而是那種最陰險的壞法:大部分驗證方式正常運作,只有一種不行。Bug report 零零星星地進來,你頭二十分鐘都在猶豫這到底是真正的事故,還是 beta 品質的 client 在做 beta 品質的事。
是真的。
Passkey 驗證在 beta Android app 上間歇性失敗。Brian 八個月前寫了 WebAuthn 流程——每個 PR 我都 review 過,但從沒親手在 staging 環境測試,所以我的理解是架構層面的,不是體感層面的。Brian 正在北海道度假,完全失聯。後來查出來的根本原因在我們這邊:beta client 配了錯誤的 passkey origin,而 WebAuthn 對 origin mismatch 毫不寬容。
這是 post-mortem 裡沒人會講的那個部分:知識瓶頸不是流程問題,而是結構性的必然。Brian 做了 passkey 功能。他知道碰了哪些資料庫 table、哪些 Athena query 能揭露失敗模式、哪些 CloudWatch metric 真正重要而哪些只是看起來嚇人卻什麼都不代表。這些知識全裝在他腦袋裡,是好幾個月的除錯和半夜部署一點一滴累積的。我從 code review 了解架構,但知道一個東西怎麼設計和知道它怎麼壞掉,是完全不同的兩回事。review 一個 PR 跟在 production 除錯之間的距離,就像看 Google Maps 跟半夜在陌生巷弄裡找路的距離。
接下來在舊世界裡會發生什麼——簡短帶過,因為如果你曾經是團隊裡那個必須除錯自己沒寫的東西的人,你已經知道了。我打開六個瀏覽器分頁。翻 Brian 的舊 Athena query,試著搞清楚哪些還有用。看著我一知半解的 CloudWatch metric,用 code review 的記憶做模式比對。Steven,我們指定的事故聯絡人,在看我的螢幕因為他想學,但我正深陷在 query 結果裡沒辦法邊做邊講——一部分原因是我自己都還在搞清楚狀況。利害關係人更新沒發出去。聯絡人角色只是照著流程擺出來的樣子,因為事故應變模板說我們需要一個。正在除錯的人忙到沒空溝通,而應該溝通的人沒有足夠的脈絡去說出任何有用的話。
這就是結構性問題。市面上有 vendor triage copilot——PagerDuty、Datadog 等等——但它們都是針對自家遙測堆疊做最佳化。我們需要的,是一個能同時跨 CloudWatch、應用程式 log、部署歷史和特定領域 Athena query 做推理的東西,而且只有一個完整了解我們技術堆疊的自建 agent 才做得到。以下所有事情,都是嘗試用那個 agent 打破知識瓶頸。
恐懼是合理的。邊界也很簡單。
讓 AI 碰基礎設施的恐懼不是杞人憂天。這個月稍早,Amazon 召開了一場全公司工程會議,因為一連串與 AI 輔助程式碼變更相關的故障——包括三月五日一場長達六小時的購物網站中斷,結帳、登入和商品定價全部癱瘓。內部簡報描述了與「Gen-AI assisted changes」相關的「high blast radius」事故。Amazon 的對策是要求所有 AI 輔助的 production 變更都需要 senior engineer 簽核。所有人的直覺都一樣:AI 靠近基礎設施很危險,所以加阻力。
我理解這份謹慎。我有同樣的恐懼。在活躍事故中,我最不想看到的就是一個 AI agent 自作主張地重啟資料庫或改 security group。
但 Amazon 的問題——以及那種加全面阻力的直覺——混淆了兩件截然不同的事。讀一個 CloudWatch metric 和修改一個 Auto Scaling group 之間有巨大的鴻溝。一個是觀察,另一個是行動。我們不會因為害怕 junior engineer 不小心按到「Terminate Instance」就不讓他們看 production dashboard。
解法是一個唯讀權限的 service account。一條 IAM policy:CloudWatch GetMetricData、RDS Performance Insights 讀取、對唯讀分析 table 的 Athena query、ALB 和 WAF metric 讀取、CloudTrail lookup。沒有 PutMetricAlarm。沒有 ModifyDBInstance。任何會改變狀態的操作都不行。
這在實務上是唯一重要的安全邊界。不是「AI 能不能存取基礎設施」,而是「AI 能不能改變基礎設施」。唯讀存取讓你多一雙眼睛,但不多一雙手。我把 policy 帶回 platform team,他們稽核後加了幾條明確的 deny,同意試行。試行至今仍在進行,沒有人要求我停下來。
十四分鐘
第二次事故發生在一個星期二。Passkey 驗證失敗再次出現,這次集中在特定地區的 Android beta 用戶。我把 CloudWatch alarm payload、beta channel 的前三則 bug report 和服務名稱貼進 triage agent。一個指令:/triage-incident --context <paste>。
Agent 同時啟動了三條並行調查線——服務層 metric、基礎設施健康度和 passkey 專屬 query——在我還在等 RDS Performance Insights 主控台渲染完成時就回報了。(那個主控台載入的時間長得令人印象深刻,彷彿每個像素都是 AWS 實習生手繪的。)
基礎設施那條線找到了。Primary RDS read IOPS 是正常值的四倍。Connection pool 到 89%。WebAuthnCredentialLookup query 的 P95 從 12ms 飆到 340ms。Agent 把這些跟 CloudTrail 的一筆記錄做了關聯——一個季度合規批次作業,對 passkey lookup 用的同一批 table 做全表掃描——在第一則 beta 用戶回報前二十分鐘啟動。
從警報到找到根本原因,十四分鐘。我一個 Athena query 都沒打。
但比速度更重要的是:我的手居然空了下來。Agent 在調查。我平常的直覺反應——跑 query、盯 dashboard、在腦中拼湊模型——已經有人在做了。所以我做了事故應變框架多年來一直拜託我做的事。我去溝通。
我開了第二個 agent session 連接 Atlassian。事故報告建立好了,調查結果一出來就灌進去。當我們確認批次作業是原因時,合規團隊在幾分鐘內就被 tag 到了,而不是通常的「某人在三十分鐘後想起來要 Slack 他們」。Steven 跟我一起看 triage 的輸出,他是在看一個有結構的診斷敘述,而不是試圖解讀我瘋狂切換分頁的動作。他開始問問題:「為什麼它把 DynamoDB latency 跟 RDS 分開檢查?」因為 passkey 流程兩邊都會打,你需要隔離瓶頸在哪一層。他在學推理過程,不是靠看我打字打到跟不上,而是讀一份會自我解釋的調查報告。
事故期間發出四則利害關係人更新。在舊世界,那個數字會是零。
從警報到緩解的總時間:二十二分鐘。我開始覺得這個工具值得信賴。這份信心很快就被打臉了。
Agent 判斷錯誤的那次,以及為什麼那才是重點
第三次事故,兩週後,agent 搞錯了。Token exchange endpoint 出現 5xx 升高。Agent 很有信心地歸咎於 DynamoDB GSI throttling——一個與錯誤開始時間完美相關的 metric spike。我差點就照著做了。但那個 GSI 只用了 provisioned capacity 的 40%,離 throttling 遠得很。Agent 做了「metric 跟錯誤同時上升」的模式比對,卻沒問幅度夠不夠大。真正的原因是那天早上部署裡一個 rate limiter 的 typo——每秒 50 個 request 而不是 500 個。差一個零,就在 agent 從沒去看的 deployment diff 裡。
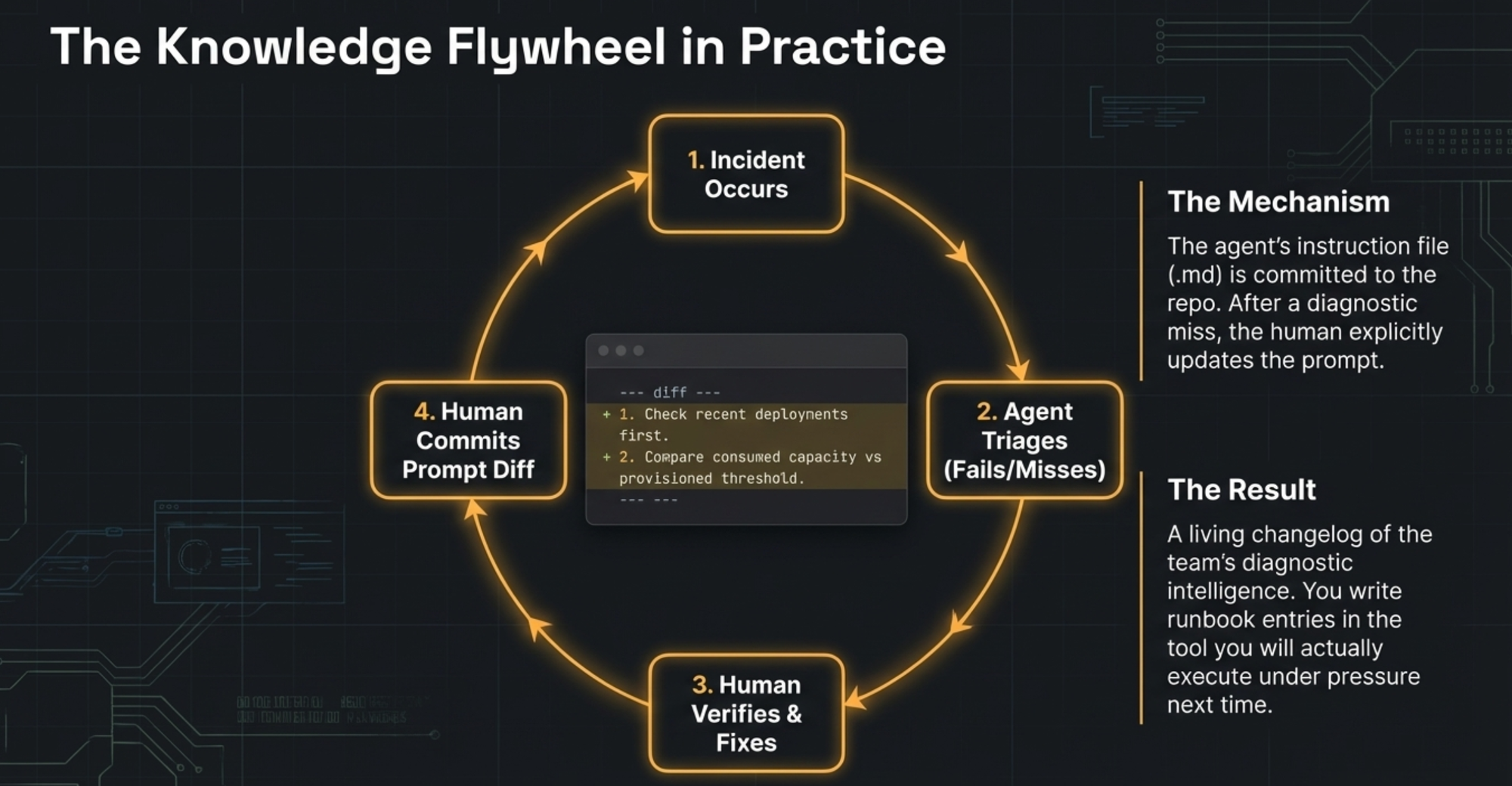
繞了十八分鐘的彎路。不算致命,但夠我們痛定思痛。從那之後我們不再把 agent 的輸出當定論,而是當偵查報告——附帶證據的假說,由人來審視追問:這個異常真的能解釋影響嗎?最近改了什麼?失敗後我更新了 skill:先檢查部署歷史,並且驗證 metric threshold 要跟 provisioned capacity 比,不能只看 spike。Steven 在第四次事故中抓到另一個缺漏:沒有檢查 ECS deployment status。他告訴我,我更新了 skill。
規律浮現了。每次 agent 判斷錯誤或不完整,我只需要告訴它:「你漏了部署歷史。更新 triage skill,讓檢查近期變更永遠是第一條調查線。」Agent 改寫了自己的 skill。下次我告訴它:「檢查 DynamoDB metric 時,要把 consumed capacity 跟 provisioned capacity 做比較——如果你只用了 40% 的額度,spike 什麼都不代表。」Agent 又更新了自己。Steven 發現 ECS 的缺漏,告訴我,我用同樣的方式轉達。一句話,skill 就吸收了教訓。

不用手動改設定檔。不用事後補 runbook。我就是跟 agent 聊它哪裡搞砸了,它自己就把 playbook 改好。修正一路疊加。Skill 被 commit 進 repo,diff 就是故事:每個改動都追溯到一次特定的事故和一個特定的錯誤。那是團隊診斷功力的 changelog,靠的不是誰有紀律去維護,而是每次真實事故逼出來的。
第五次事故
到了第五次事故,那些一句話的修正已經滾成了我始料未及的雪球。Skill 會先檢查部署歷史。會把 metric threshold 跟 provisioned capacity 做比較。會檢查 ECS deployment status。全都是被告知一次就學會的教訓。在 triage 階段我幾乎不用介入。Agent 並不完美——偶爾還是會標記無關的 metric,嚴重性評估也偏高一檔。但它的表現已經像一個在團隊待了一年的人,不再是第一天那個什麼都不懂的菜鳥工具。
Steven 上週獨立使用了它。一個警報觸發:token refresh endpoint 的 401 response 升高。他跑了 triage skill。Skill 先檢查近期部署(沒有),掃過基礎設施 metric,然後縮小範圍到 token validation 子系統。十二分鐘找到根本原因——上游 identity provider 更改了 JWKS endpoint 的回應格式,破壞了我們的 key rotation。Steven 建了事故報告、跟利害關係人溝通、協調修復。他不需要我。他沒有 Slack 我。我是隔天早上從 post-mortem 文件裡才知道的。
那個瞬間我知道,結構性問題真的被解掉了。不是緩解,是破局。Steven 端到端地處理了一次事故,用的是一個從每次先前錯誤中學習過的 skill——而那些錯誤,我只是一句一句地講給它聽。
數字怎麼說

量測這件事,我想講白一點。我們沒有跑對照實驗。我們沒有乾淨的前後比較 metric,因為「之前」根本沒有被 instrument。我們有的是 Slack 訊息、事故報告和我自己筆記裡的時間戳。
在 triage agent 之前,我們從警報到找到根本原因的中位數——根據我能重建的 2025 年六次事故——大約是七十分鐘。快的三十分鐘(見過的問題,靠肌肉記憶就能斷),慢的四小時(全新的壞法,得從頭摸索)。
有了 triage agent 之後,五次事故的中位數是十八分鐘。區間是十二到二十八。二十八分鐘那個離群值是第三次事故,agent 判斷錯誤,我們在錯誤線索上浪費了時間。
我更在意的數字:活躍事故期間發出的利害關係人更新數。之前:中位數一則,通常是在修復已經在進行時才發出。之後:中位數四則,第一則在警報後十分鐘內就發出。這才是真正被打通的環節。Triage agent 不只加速了診斷——它把人類從 query engine 的角色裡釋放出來,去做人類真正擅長的事:讓等答案的人不再乾等。
工程師本來就該做的事
算事故成本,大家習慣盯停機分鐘數。那當然重要。但真正吃人的隱性成本——而且會逐季複利的——是知識壟斷。每一次只有一個人能做 triage 的事故,都讓那個人更不可或缺,讓團隊更脆弱。資深工程師變成 SPOF(單點故障),不是他們自願的——事故應變天生就是師徒制,永遠不會有夠多的事故讓每個人都練到,而真正發生的那些又太急,根本沒餘裕拿來教學。
Triage agent 沒有取代我。它揭露了我一直以來本該在做什麼。
這些年做事故應變,我以為自己的價值就是診斷問題。當那個 query 記得最多、metric 看得最懂、系統壞法最熟的人——或者至少在真正熟的人不在時,能頂著上場撐住。大家也是這樣期待我的。但診斷問題從來不是團隊的難處——它之所以難,只是因為知識被鎖在一個人的腦袋裡,而那個人不一定在場。真正的難處,那個影響客戶、利害關係人和業務的部分,是在壓力下清楚溝通、跨團隊協調、以及對嚴重性和緩解取捨做判斷。我沒有在做這些,因為我正忙著當人肉 query engine。
Agent 接手了 query engine 的活。剩下的,才是真正重要的工作:跟人講話、拍板、帶人。回頭看,所謂的「英雄工程師」一點都不英雄。不過是一個碰巧更有經驗,或者打字比較快的瓶頸。

我不知道第六次事故會教 skill 什麼。那正是重點——它不需要在第一天就完整,只需要每次事故之後比上次更強。而團隊需要信任它到願意用、又懷疑它到願意改。到目前為止,這兩條線都不難守住。