AI 典範轉移 Ep.3:從複製貼上到 Commit——Skill 如何取代了我的 Prompt 收藏夾
從複製貼上 ChatGPT,到 skill commit 進 codebase 的演化——為什麼介面而非智慧,才是一直以來的瓶頸。


這個系列前兩集講的是特定的工具——一個監控 skill、一個 triage agent。但說實話,那些只是一段更長旅程的終點,而這段旅程的起點跟所有人一樣:把文字複製貼上到聊天視窗裡,然後祈禱輸出有用。
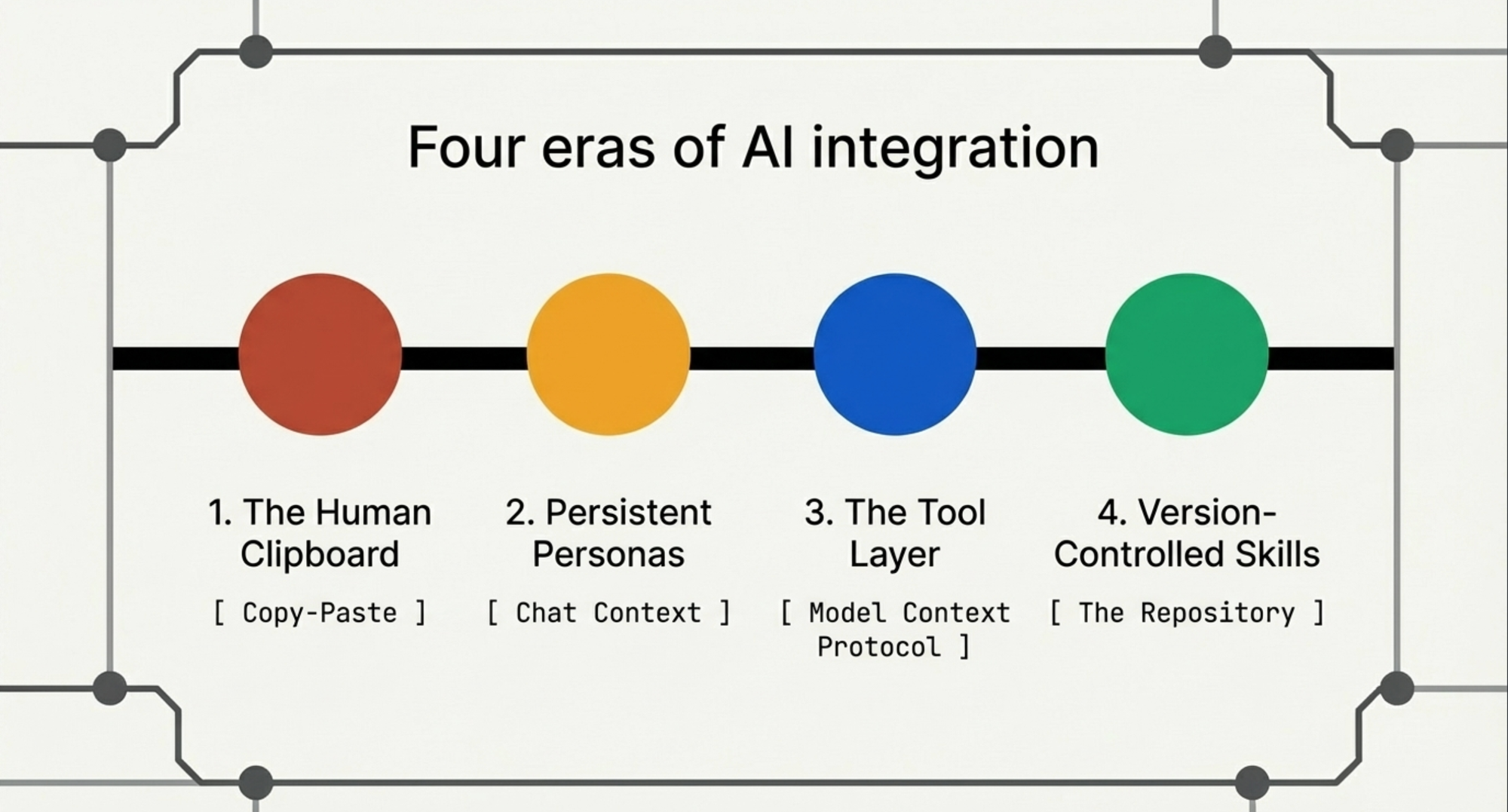
這一集講的是旅程本身。兩年內,我和 AI 之間的介面換了四次,而每一次換,帶來的改變都比模型本身的進步更大。
人肉剪貼簿
2022 年底、2023 年初。ChatGPT 橫空出世。我記得那段時間在紐約參加一場研討會,講者問台下有沒有人用過好的 chatbot。五百人的會場,舉手的只有兩個。但 ChatGPT 不像我見過的任何 chatbot——它不是在關鍵字上做 pattern matching 然後吐罐頭回覆。它能推理,或者至少表演出一種令人信服的推理。我是真的被震撼到了。
我最先拿它來做的是摘要。一張 Zendesk ticket 進來:900 個字,真正的錯誤訊息埋在第六段,夾在對我們文件的抱怨和要求打電話之間。我把整段複製貼上到 ChatGPT。「幫我摘要這張 ticket,然後草擬一張 Jira story。」出來一份摘要和一張 story。還行。不一致,但還行。
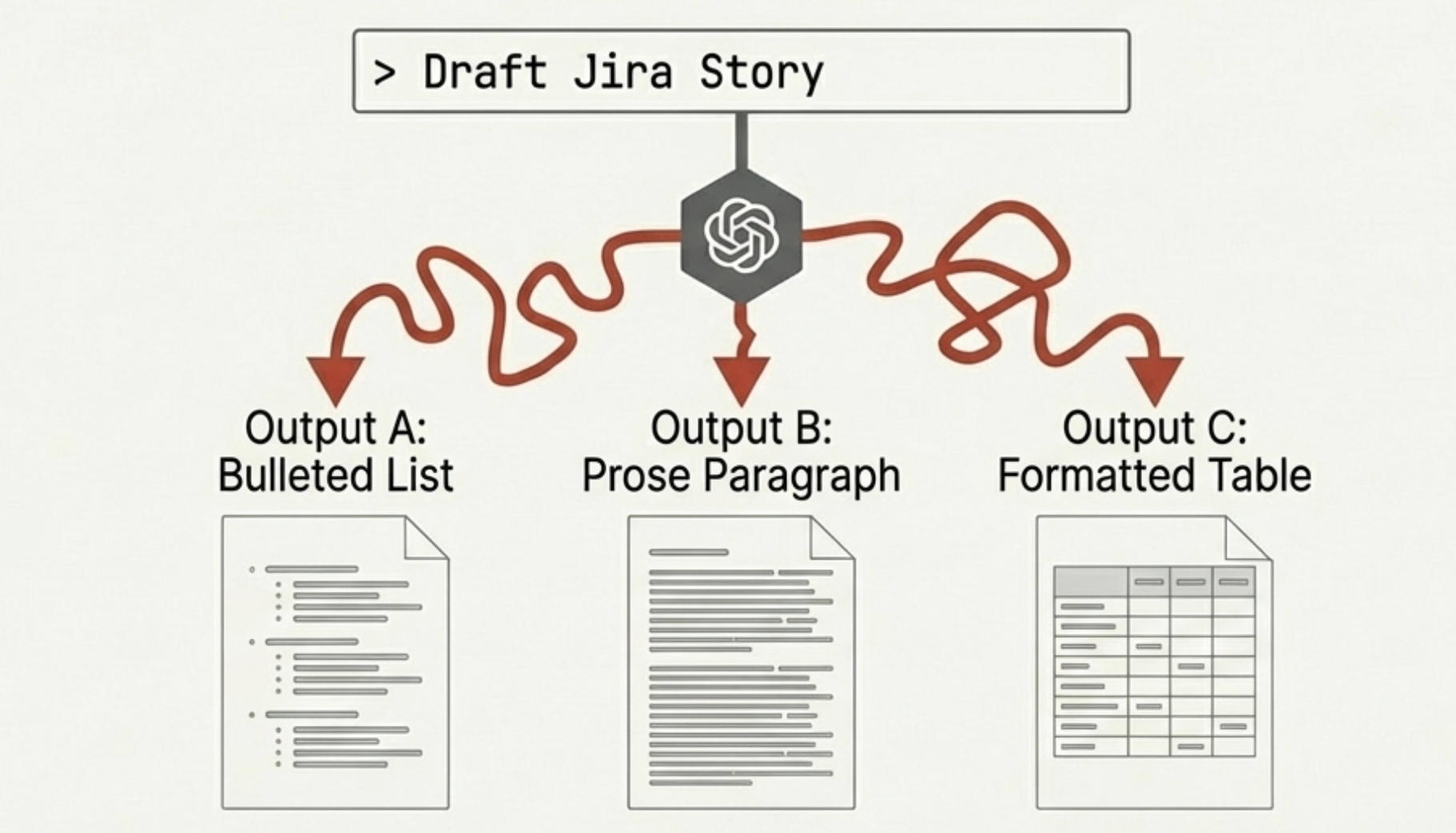
不一致是第一道裂縫。每次輸出的格式都不一樣。LLM 本質上是個隨機過程——同樣的 prompt、同樣的輸入,每次產出不同的結果。當你想在團隊工作流程裡建立在這個基礎上,「每次都不一樣」不是功能,是稅。
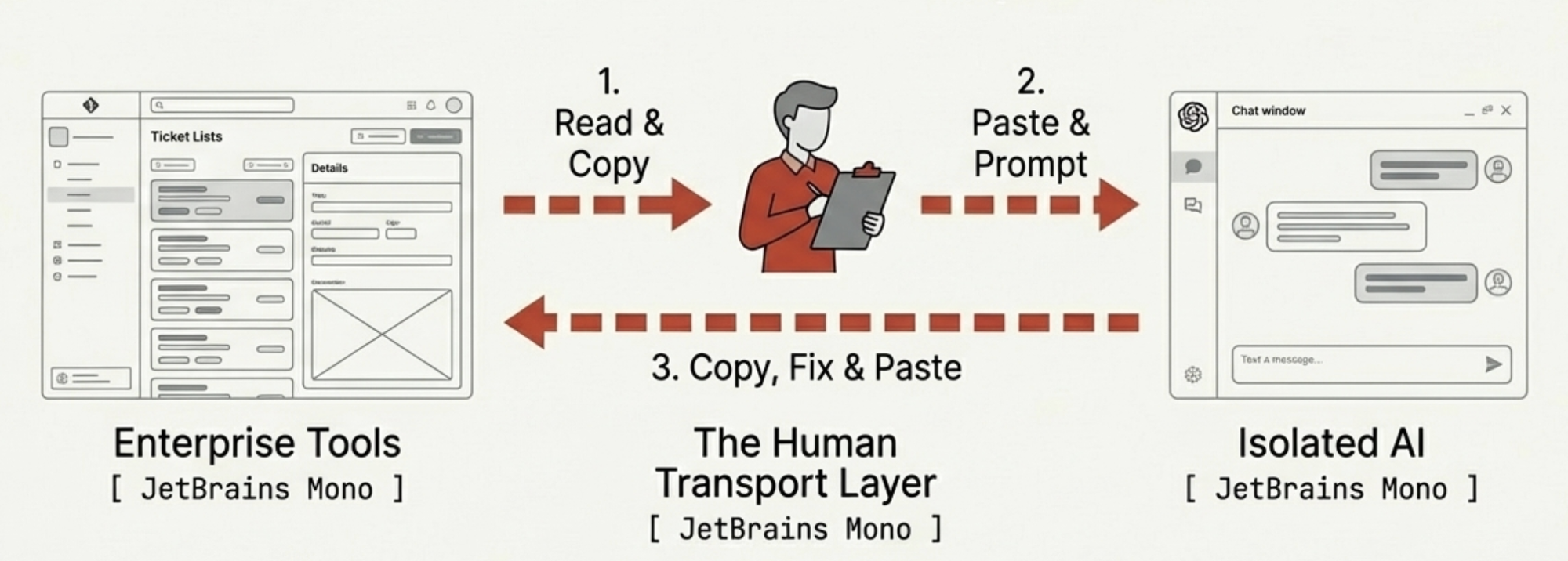
於是我做了任何工程師都會做的事:寫下來。一個個人 prompt 收藏夾——按任務分類的文字檔。一個用來摘要 Zendesk ticket。一個用來草擬 Jira story。一個用來寫 incident post-mortem。每個都經過反覆試錯打磨。回頭看,我當時其實是在為一個還不存在的 API 手刻一套個人 SDK,用複製貼上當 transport layer。
這招有用。但也意味著每次互動都是同一套儀式:找到對的 prompt、把 context 複製貼上進去、把輸出複製貼上出來、貼進實際的工具裡、手動修正 LLM 搞錯的部分。我是一塊有主見的人肉剪貼簿。AI 很強大但被隔離了——它住在一個瀏覽器分頁裡,跟每一個真正的工具之間隔著我的剪貼簿這層膜。
當 AI 有了個性
然後來到 persona 時代。Gemini Gems、Claude Projects、ChatGPT custom GPTs。賣點是:不用每次貼 prompt 了,你建一個持久的 context。一個 persona。你描述角色、上傳參考文件、設定語氣。
我建了好幾個。一個 database migration 專用的 persona,熟悉我們的 schema 慣例。一個 support case 分析的 persona,知道我們的產品層級和常見故障模式。一個架構設計的 persona,裝載了我們的 service map 和 API 合約。一致性進步了——support persona 每次都會產出有 acceptance criteria 的 Jira story,因為我告訴它要這樣做。Prompt 消失了,取而代之的是更持久的東西,算有點進步。

但根本的拓撲沒有變。我還是那個 transport layer。把 Zendesk ticket 複製進 support persona,讀輸出,複製進 Jira。AI 更聰明也更一致了,但它還是在聊天視窗裡,而我還是那個在聊天視窗和現實之間搬運資料的人。
我把 persona 分享給團隊,透過連結。他們用了。他們也各自微調了一點,然後我們就有了三份分歧的副本,沒有任何方式可以合併。我們分享知識的方式跟 2004 年分享 Word 文件一樣——寄副本出去,然後祈禱沒人做出衝突的修改。
Tool Layer 到了,然後立刻暴露了真正的問題
MCP 改變了遊戲規則。Model Context Protocol 給了 AI 一個標準化的方式跟實際工具溝通——不是透過我的剪貼簿,而是直接連接。Jira、Confluence、GitHub、AWS、資料庫。隔離解除了。
我從聊天客戶端搬到了 Cursor 和 Claude Code。不再把 support case 複製進聊天視窗了,我可以直接說「讀這張 Zendesk ticket 然後建一張 Jira story」,agent 會透過 Zendesk 整合讀 ticket,透過 Jira MCP tool 建 story,直接填入欄位。沒有剪貼簿。沒有複製貼上。
大概有兩個禮拜,我以為這就是終極形態了。然後格式問題又回來了。

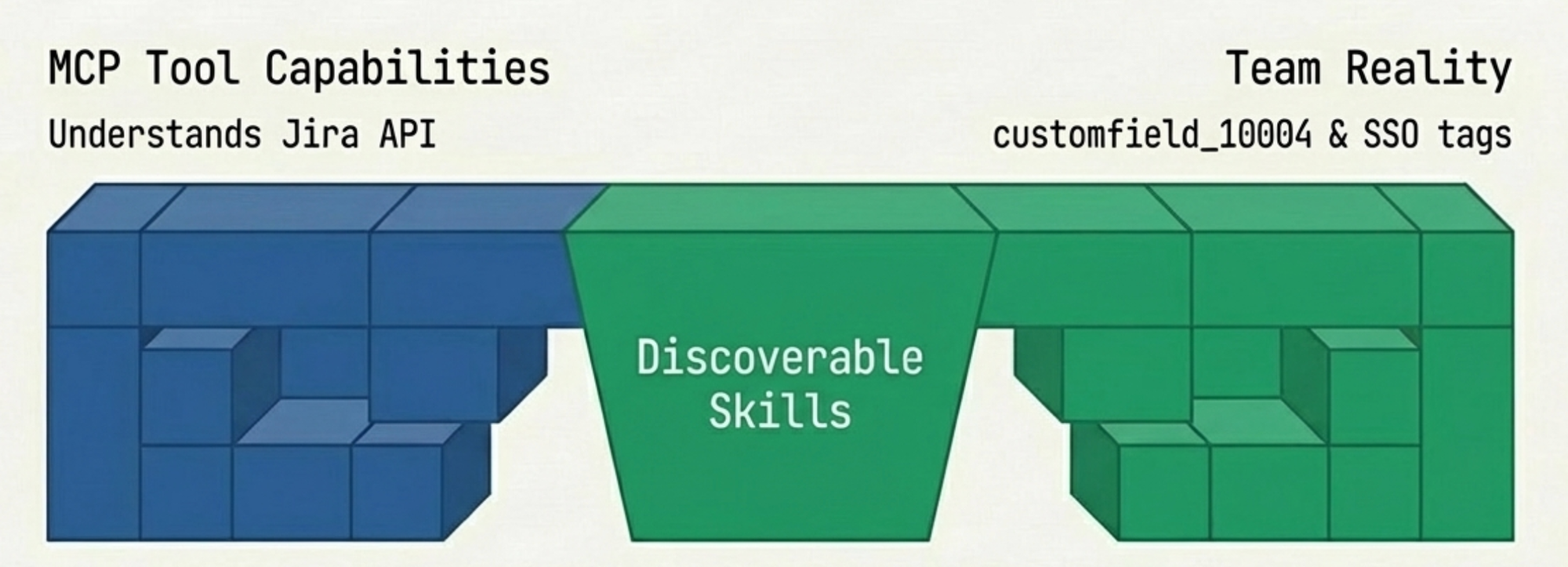
MCP 讓 AI 可以使用工具。但它沒有讓 AI 知道你的團隊怎麼使用這些工具。我們團隊對 SSO 子系統有特定的 component tag。我們對來自 support case 的 story 和來自內部規劃的 story 有不同的命名慣例。Story point 欄位是 customfield_10004,不是每個 LLM 第一次都會猜的那個比較直覺的欄位名。
Agent 可以建 Jira ticket。但建出來是錯的。Component 錯、label 格式錯、story point 填錯欄位。每次修正都是我在對話裡打的一句 prompt,下一個 session 就忘了。我又回到了記 prompt 的日子——不是因為 AI 缺乏能力,而是因為它缺乏我們團隊的 context。
Mario Zechner 說得好:「與其爭論 MCP 還是 CLI,不如開始打造更好的工具。Protocol 只是水管。」他說得對。他的 benchmark 顯示,設計良好的情況下,MCP 和純 CLI 工具的表現一模一樣——一個 225 token 的 CLI wrapper 配上好的 README,勝過一個 18,000 token 但文件寫得爛的 MCP server。問題從來不是 protocol。是團隊怎麼把自己的慣例編碼進給 agent 用的工具裡。MCP 是工具供應商的介面。它暴露的是 Jira 能做什麼。它對於 Jira 應該怎麼被一個三人 SSO 團隊使用——用什麼 component tag、什麼 story 格式——一個字都沒說。那個落差——capability 和 convention 之間的——才是所有摩擦真正住的地方。
從快捷鍵到可以 Commit 的東西
Custom command 是第一次嘗試填補這個落差。Claude Code 裡的 slash command:你把一段長 prompt 寫在檔案裡,給它一個名字,用 /my-command 呼叫。Prompt 載入,agent 照指令走,你不用每個 session 重新打一次慣例就能拿到一致的輸出。
我建了一堆。/create-support-ticket 包含了我們所有 Jira 慣例。/write-postmortem 有我們的 incident report 結構。/draft-epic 知道我們怎麼把 feature 拆成 story。更好了。但很僵硬。
Custom command 就是一段加了捷徑的長 prompt。它不能動態引用外部檔案。它不能根據輸入類型調整。而且最關鍵的,agent 不能自己發現它——你必須知道這個 command 存在然後明確地呼叫它。如果一個隊友在處理 incident 但不記得有 /write-postmortem 這個東西,他就會從頭寫 post-mortem。知識被編碼了,但不可被發現。
然後 skill 出現了,而這裡我需要誠實地說它是什麼、不是什麼。
Skill 在 Claude Code 裡是一組指令、references 和 sub-command 的集合,agent 可以自動發現並執行。當 agent 看到一個任務符合某個 skill 的描述,它可以在使用者沒有明確呼叫的情況下載入並執行。Skill 可以引用外部檔案——我們的 Jira component mapping、incident severity rubric——而且它可以呼叫 MCP tool,所以整個鏈條就接上了:skill 編碼我們團隊的慣例,MCP tool 把它們執行在真實系統上。
我的工作流程變成:/jira-skill "customer reports SAML integration broken, see Zendesk #4521"。Skill 偵測到這是一張 support 來源的 ticket,載入 convention reference,套用正確的 component tag 和 label 格式,填入 customfield_10004,然後呼叫 Jira MCP tool。一次呼叫,輸出正確,不用修正。
但真正的價值不在呼叫本身。而是當 agent 在自主執行一個更大的任務、遇到一個 skill 能處理的子任務時會發生什麼。它找到 skill、載入它、使用它。慣例在我不在 loop 裡的情況下被套用。團隊的知識不只是被編碼了;它可以被 agent 當作一個可組合的原語來使用。
Skill 一開始確實是特定 agent 專用的,但生態系正在趨同。像 Vercel 的 skills CLI 這類專案已經可以把同一個 skill 定義分發到四十多種 agent 上,從 Claude Code 到 Cursor 到 Gemini CLI。基本格式——一個 Markdown 檔案加上名稱、描述和指令——正在變成一個共享的原語。進階功能在不同 agent 間仍有差異,但核心模式是可攜的,而且越來越可攜。
改變一切的那次 Commit
故事在這裡繞回前兩集。
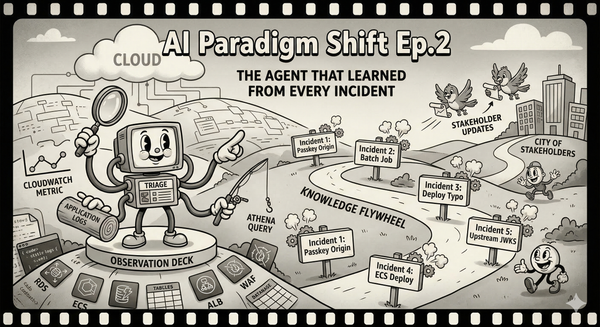
Episode 1 的監控 skill 和 Episode 2 的 triage agent 之所以特別,不是因為它們用了 AI。是因為它們被 commit 進了 repository。它們活在版本控制裡。它們透過 pull request 演化。可以 review、可以 diff、可以執行。
以前分享 AI context 意味著傳一個 Gem 或 Project 的連結。現在意味著把 skill commit 進 repo。新工程師可以讀 skill 理解團隊怎麼處理 support case,或者直接跑它,開箱即用地拿到正確的行為。
當一個隊友發現我們的 triage skill 缺少 ECS deployment 檢查——Episode 2 的事——我們沒有更新 wiki 頁面,也沒有發一則兩天後就被淹沒的 Slack 訊息。我們更新了 skill 然後 commit 了變更。Diff 講述了故事:「新增 ECS deployment status 檢查作為第一個調查步驟,因為 Incident #5 顯示 deployment 變更是最常見的 root cause。」營運知識,有版本控制、可 review、可立即執行。

Zechner 提到,用 ad-hoc 的工具,「你必須自己想出一套結構來建造和維護它們。」對一個人開發來說,這種自由是資產。對一個團隊來說,它是負債。三個人各自維護 ad-hoc 工具但沒有共享慣例,會以跟我們當初 persona 分歧完全一樣的方式分歧。共享 repo 裡有版本控制的 skill,是讓我們保持一致的強制函數。
壓縮一下這個演化:複製貼上、然後 persona、然後 MCP、然後 skill。每一步都壓縮了意圖和行動之間的一層摩擦。複製貼上用一塊人肉剪貼簿隔開它們。Persona 減少了 prompt 負擔但人類還是 transport。MCP 移除了 transport 但沒帶走慣例。Skill 編碼了慣例,並讓它們可以被發現。
介面才是瓶頸
過去兩年我一直假設限制因素是模型智慧。更好的模型會產出更好的結果。狹義上來說這沒錯。但真正改變我日常工作的進步,不在智慧。在介面。
從複製貼上到 persona,每個任務省了五分鐘。從 persona 到 MCP,省了十分鐘。從 MCP 到 skill,根本沒省時間——省的是一致性,而一致性才是三個人用同一套慣例跑正式環境時真正重要的東西。時間節省線性累積。一致性節省幾何累積,因為每一個不一致都會產生下游修正,而那些修正又會製造自己的不一致。
我的 prompt 收藏夾消失了。不是被刪除——是被遺棄。複製貼上成為時代的化石。裡面的知識已經遷移到 commit 進 repository 的 skill 裡,agent 可以發現它們,每一次 incident 和 sprint 都在改善它們。全團隊用同一套 skill,當其中一個人教了 skill 新東西,下一次執行所有人都受益。
這個系列裡的典範轉移不是「AI 能做事了」。轉移在於,人類意圖和機器行動之間的介面,從一個多步驟、有損耗、手動的過程,坍縮成了一個看起來像 function call、感覺像在跟一個讀完了你從來沒寫的文件的隊友說話的東西。
我從來沒寫那些文件,因為我從來沒有時間。現在我不用寫了。Skill 就是文件。它們只是碰巧還能執行。