Replace MCP with Skills and Why
The slow unraveling of our MCP integration, and why we ended up replacing it with documented curl patterns in skill


MCP was genuinely great at first
When we first wired up mcp-atlassian to Claude Code, it felt like magic. "Create a Jira ticket for this bug." Done. "Update the Confluence page with the new architecture." Done. The MCP server handled authentication, request construction, Atlassian Document Format – all the tedious plumbing that makes the Atlassian API unpleasant to use directly. We had 71 tools at our fingertips and didn't have to think about any of them.
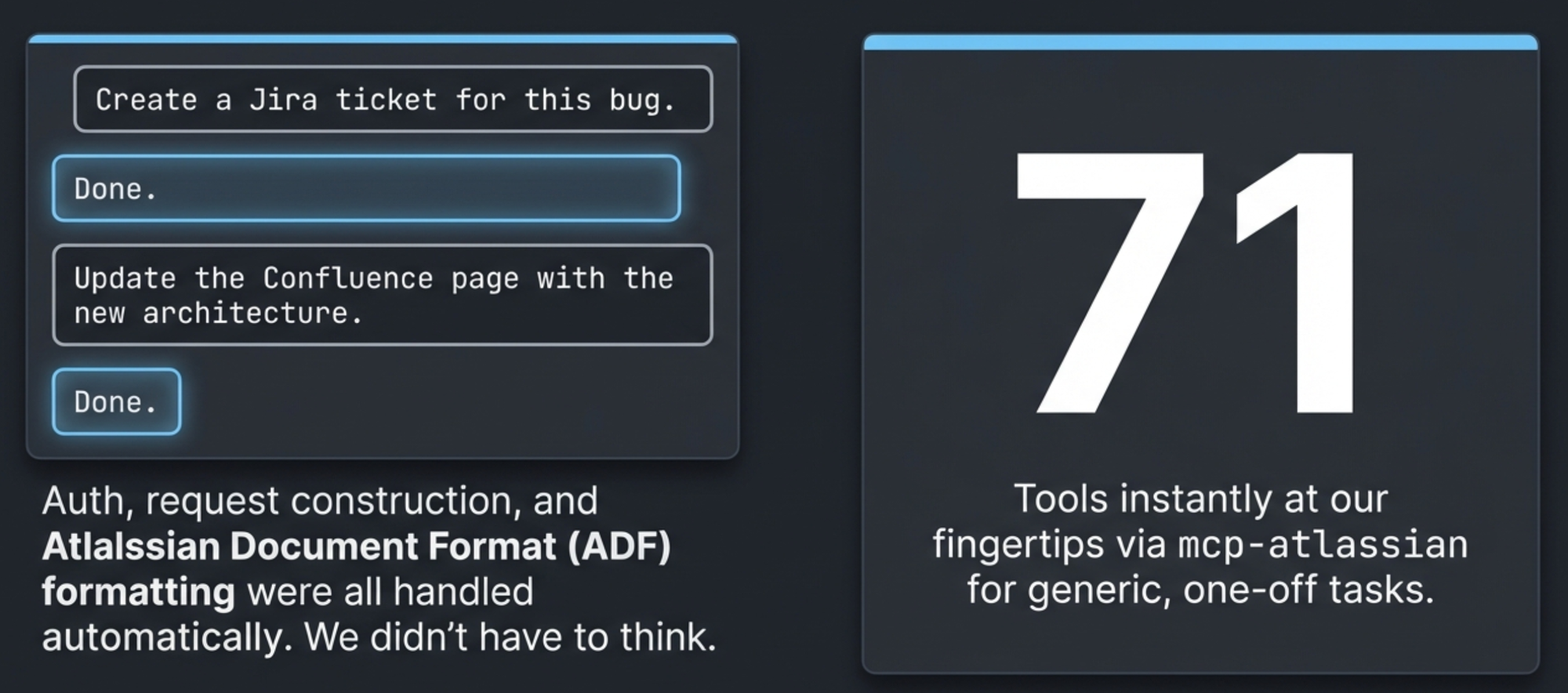
For generic, one-off tasks, this was perfect. The problem started when we wanted things done our way.
We got tired of repeating ourselves
Every time we created a ticket, we had to say: "Use project Cloud-Team. Set the component to Cloud-Core. Prefix the title with [Cloud]. Assign it based on the current sprint rotation." Every time we created a Confluence page, we had to specify the space, the parent page, the heading structure. And half the time the formatting came back wrong anyway -- list items with broken bold text, headings where there shouldn't be headings, descriptions that needed a second pass to fix.
We were spending as much time correcting output and restating preferences as we would have spent doing the work manually. The tool was fast but imprecise, and precision is what you need when every ticket and every page feeds into your team's workflow.

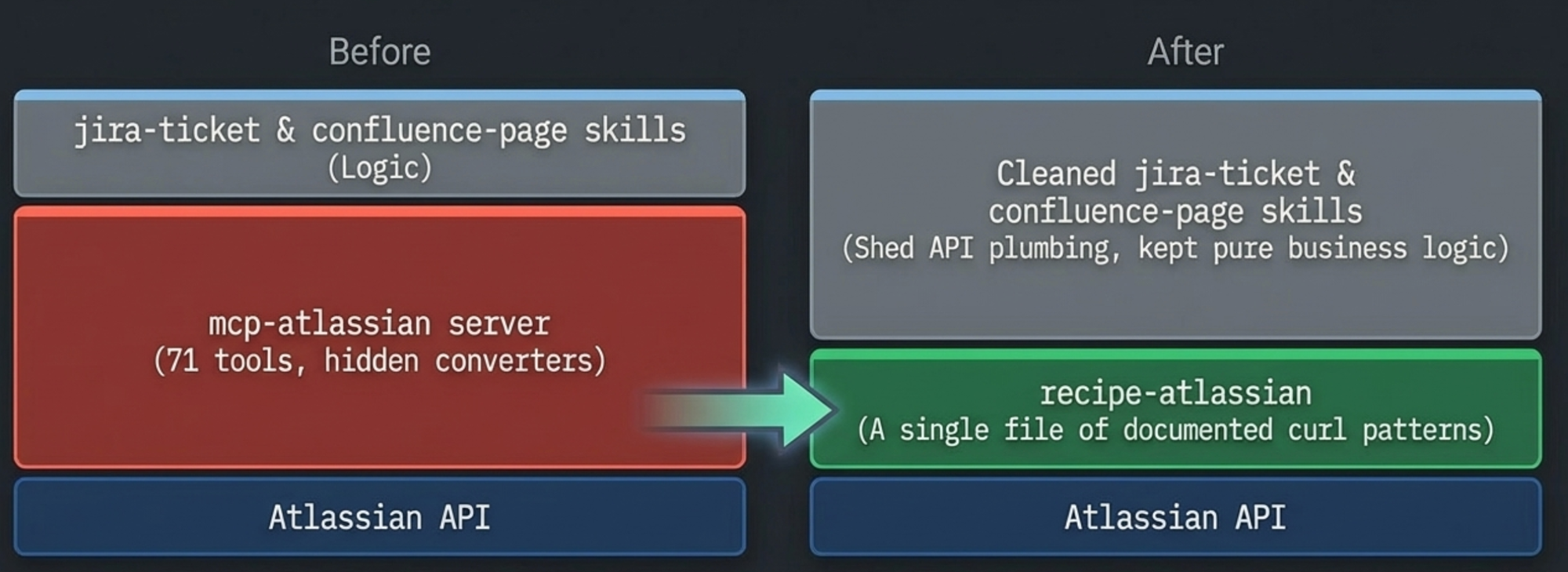
So we built skills on top. A jira-ticket skill that encoded our project defaults, title conventions, component assignments, and custom field handling. A confluence-page skill that knew our space structure and formatting standards. These skills invoked the MCP tools underneath -- jira_create_issue, jira_update_issue, confluence_create_page -- but wrapped them in our team's specific logic.
This worked. For a while.
Then the MCP upgraded and broke everything
The mcp-atlassian package shipped a new version, and our skills broke. Tool names changed. Parameter formats shifted. Behaviors we relied on silently disappeared.
We rewrote our skills to match the new version. And in doing that rewrite, we started noticing things we'd been blissfully ignorant of.
The Jira REST API has multiple versions. Version 2 accepts Markdown-ish text for description fields. Version 3 requires Atlassian Document Format -- a JSON structure with typed nodes, marks, and nested content. The MCP server was converting our Markdown input into ADF internally, and that conversion was where five of our six documented bugs lived: bold text inside list items rendered wrong, underscores triggered false italics, hash characters were parsed as headings, leading spaces vanished, horizontal rules appeared where they shouldn't.
We'd been debugging formatting issues at the wrong layer. The bugs weren't in our skills or in our input -- they were in a Markdown-to-ADF converter hidden inside the MCP server, a converter we couldn't see, couldn't control, and couldn't fix.
The file upload gap and the Docker problem
Two more friction points pushed us further from MCP.
First: mcp-atlassian didn't support file uploads. That sounds minor until you realize it means no image attachments on Confluence pages, no uploaded diagrams, and critically -- no Mermaid diagram macros. Confluence renders Mermaid diagrams through the mermaid-cloud macro, which references an attached image. Without file upload support in the MCP, we had to do these operations manually: upload the file through some other means, get the attachment ID, then construct the page content referencing it. Half the workflow was inside the MCP abstraction and half was outside it, which is worse than having all of it outside.
Second: the Docker overhead. The version of mcp-atlassian we started with only ran in Docker. Each Claude Code session spawned its own container. Run three sessions in a morning -- reviewing a PR, creating tickets, updating docs -- and you'd have three containers alive, each holding a connection to Atlassian. Nobody was cleaning them up reliably. We'd find stale containers days later.
We eventually switched to a version that ran natively via uvx, which eliminated the container sprawl. But it was another migration, another set of configuration changes, another afternoon spent on tooling plumbing instead of actual work.
The accumulating weight of workarounds
By this point we had:
- A skill layer on top of MCP to encode team-specific behavior
- Six documented converter bugs with workarounds baked into our skills
- A mandatory two-step process for issue creation (create without custom fields, then update to add them, because the converter broke when custom fields were in the same call)
- Manual file upload workflows for anything involving attachments
- Memory files documenting MCP quirks so Claude wouldn't repeat mistakes
- A history of one breaking upgrade already absorbed
We were maintaining more infrastructure around the MCP than the MCP was saving us. And we were still hitting formatting bugs on every third Confluence page update.
That's when I read Mario Zechner's "What If You Don't Need MCP?," and it reframed the problem for me.

Zechner's argument is deceptively simple: MCP servers need to cover all bases, which means they ship large numbers of tools with lengthy descriptions, all permanently consuming context. He measured it. Playwright MCP: 21 tools, 13.7k tokens -- 6.8% of Claude's context window, gone before you ask a single question. Chrome DevTools MCP: 26 tools, 18k tokens, 9% of context. Our mcp-atlassian was worse: 71 tools, ~15-20k tokens, loaded into every session regardless of whether that session would ever touch Jira.
But the context cost was only his first point. The deeper problem is composability. MCP outputs route back through the agent's context before they can be persisted or combined with other results. Every API response, every search result, every page content fetch -- it all lands in the context window as intermediate state, crowding out the space you need for actual reasoning. With a curl command, the agent can pipe output to a file, chain it with jq, or redirect it entirely -- the result doesn't have to pass through context at all.
His solution was minimal bash scripts documented in a README. The agent reads the README, understands the tools, calls them directly. His browser toolkit went from thousands of tokens of tool schemas down to 225 tokens of documentation. And the key insight behind the savings: "This efficiency comes from the fact that models know how to write code and use Bash. I'm conserving context space by relying heavily on their existing knowledge." You don't need a tool schema to teach Claude how to make an HTTP request. Claude already knows curl. What it needs is the authentication pattern and the endpoint structure -- documentation, not abstraction.
Zechner also pointed out something we'd been experiencing without naming it: MCP servers are hard to extend. You can check out the source and modify it, but then you have to understand their codebase on top of your own. When our MCP server's converter broke, we couldn't just fix the converter -- we'd have needed to fork the project, understand its ADF conversion pipeline, patch it, and maintain our fork. Instead we documented the bugs and worked around them. That's the tax you pay for an abstraction you don't control.
We weren't just paying context overhead. We were paying maintenance overhead, debugging overhead, upgrade-compatibility overhead, and extensibility overhead – all to rent an abstraction that was hiding its own bugs from us, whose outputs weren't composable, and whose tool schemas consumed context whether we used them or not.

A skill is all we need
The replacement architecture has three pieces, same as before, but the bottom layer changed completely.
recipe-atlassian replaced the MCP server. It's a single skill file containing documented curl patterns for every endpoint we use -- authentication, issue CRUD, search, Confluence page operations, file uploads, the works. No SDK, no wrapper functions. Just examples that Claude reads and adapts.
jira-ticket and confluence-page stayed as our team-specific workflow layers, but got cleaner. They stopped referencing MCP tool names and started saying "use the recipe-atlassian skill for all API calls." All the team logic -- project defaults, title conventions, assignee rules, verification workflows -- remained untouched. The skills shed their API plumbing and kept only business logic.
The critical design decisions:
Claude generates ADF inline. Instead of converting Markdown through a buggy middle layer, Claude reads a 200-line ADF schema reference and constructs the JSON directly. Five converter bugs disappeared in one stroke. The same approach works for Confluence -- Claude writes storage format XHTML natively, which gives us access to every Confluence macro including Mermaid diagrams, code blocks with language hints, info panels, and table of contents. The MCP's Markdown conversion couldn't reach most of these.
Every API call is a visible curl command. When something fails, you see the exact request and response:
curl -s -u "${JIRA_USERNAME}:${JIRA_API_TOKEN}" \
-X POST \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-d '{
"fields": {
"project": {"key": "PROJ"},
"summary": "Issue title",
"issuetype": {"name": "Task"},
"description": {"version": 1, "type": "doc", "content": [...]}
}
}' \
"${JIRA_URL}/rest/api/3/issue"
No opaque intermediary. No hidden conversion. No wondering which layer broke.
File uploads just work. Curl handles multipart form uploads natively. The thing MCP couldn't do at all became a straightforward curl call with -F "file=@diagram.png". We could finally do full Confluence page updates with Mermaid diagrams in a single workflow.
What the abstraction was hiding
Going direct surfaced things the MCP had been quietly handling -- and sometimes quietly mishandling.
URL format mismatch. JIRA_URL is https://your-org.atlassian.net with no path suffix. CONFLUENCE_URL is https://your-org.atlassian.net/wiki with /wiki included. Our first Confluence curl call produced .../wiki/wiki/api/v2/pages. A 404 on attempt one. Trivial to fix, but we'd never learned the actual URL structure because the MCP constructed URLs for us.
ADF-typed custom fields reject strings. We tried clearing a field by setting it to "". The API said: "Operation value must be an Atlassian Document". The field was ADF-typed -- it needed {"version": 1, "type": "doc", "content": []}. The MCP had been silently coercing types.
Deprecated search endpoint. The old GET /rest/api/3/search is deprecated. The replacement is POST /rest/api/3/search/jql with token-based pagination. The MCP was still on the old endpoint. Going direct put us on the current API.
Every one of these was a thing we should have understood about our own API surface. The MCP wasn't just abstracting the HTTP calls -- it was abstracting our understanding of the system we depend on.
The numbers
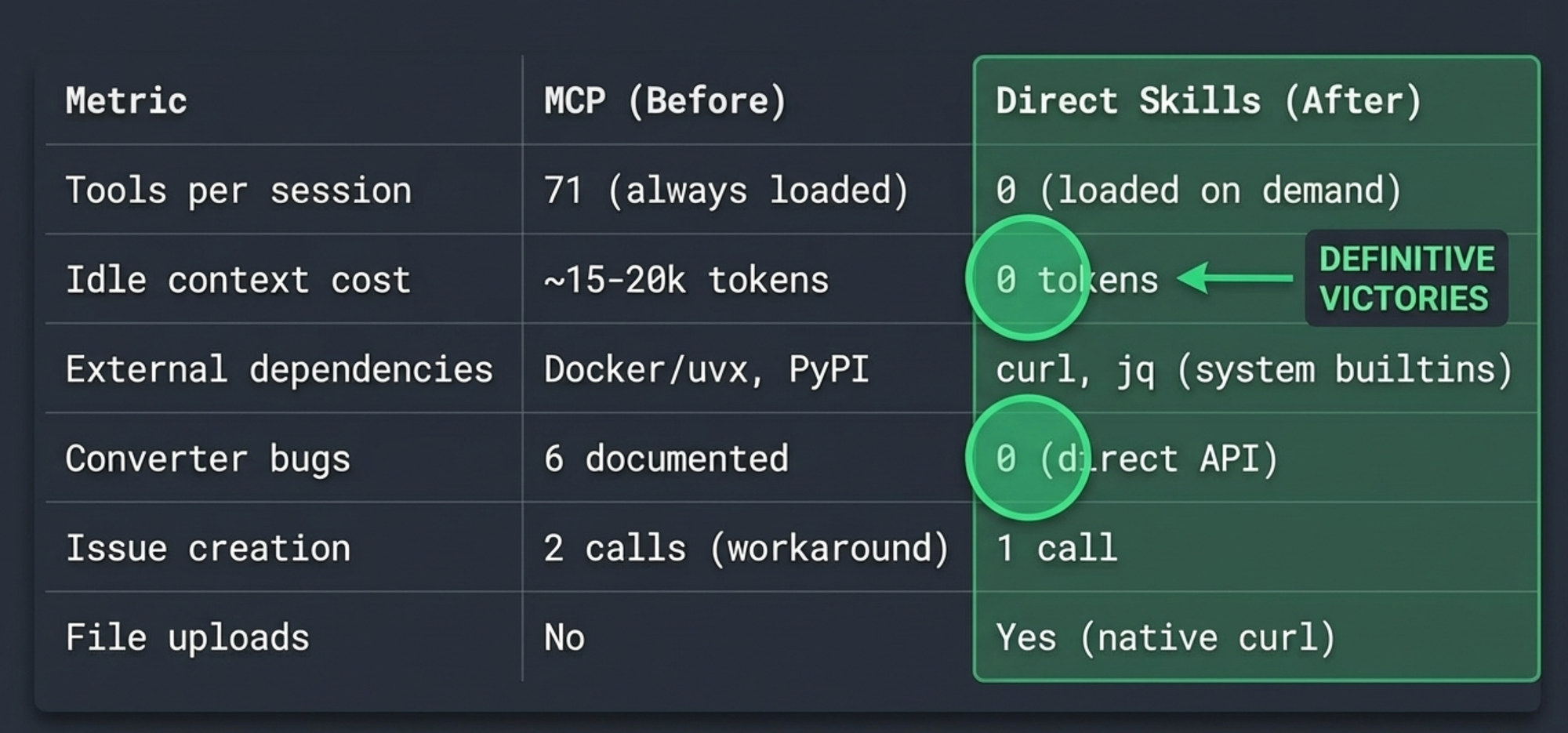
| Metric | MCP (before) | Skill (after) |
|---|---|---|
| Tools registered per session | 71 (always loaded) | 0 (loaded on demand) |
| Idle context cost | ~15-20k tokens | 0 tokens |
| External dependencies | Docker or uvx, mcp-atlassian PyPI | curl, jq (system builtins) |
| Converter bugs/workarounds | 6 documented | 0 (direct API) |
| Issue creation | 2 calls (bug workaround) | 1 call |
| File upload support | No | Yes (native curl) |
| Breaking upgrades absorbed | 1 (with full skill rewrite) | N/A (we control the patterns) |
The zero idle cost is the headline number. Skills load on demand – if a session doesn't touch Jira, zero tokens are spent on Atlassian tooling. With MCP, those 71 tool schemas were in context from session start regardless of whether you needed them.
But the number I care about most is the last one. We will never again have a dependency upgrade break our team's workflow. The curl patterns in our recipe skill talk directly to Atlassian's REST API. If Atlassian changes an endpoint, we update one line in one file. No waiting for an MCP maintainer to ship a fix. No hoping the fix doesn't introduce new converter bugs. No rewriting our workflow skills because tool names changed.
The slow unraveling
Looking back, the trajectory was predictable. MCP gave us fast access to an unfamiliar API, and that was valuable. But as our needs got specific -- team conventions, formatting standards, attachment workflows, custom fields -- the abstraction started fighting us instead of helping us. Each workaround was small. Each bug was tolerable. Each upgrade was absorbable. But they accumulated, and at some point we crossed the line where the MCP was costing more than it saved.
The migration took one session. The six converter workarounds disappeared immediately. File uploads started working. Docker containers stopped piling up. And now when a curl call returns a 400, we see exactly why -- because there's nothing between us and the API but a documented pattern and a shell.
I don't think MCP is wrong. For exploring an unfamiliar API, for broad tool discovery, for integrations maintained by someone else -- it earns its keep. But for a focused integration where you've accumulated a bug list and a workaround file and a history of breaking upgrades? At that point you're not using a tool. You're maintaining a dependency. And the question becomes whether that dependency is giving you more than curl would.
For us, the answer was no.