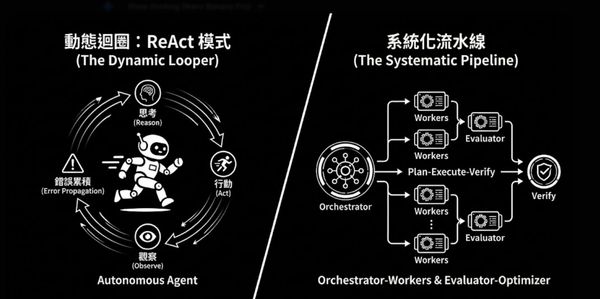
Setup local “claude code” alternative — free, open source, and no code
The horizon for edge AI is getting closer and closer. How I use lm studio and open code to build a completely free and local claude code alternative

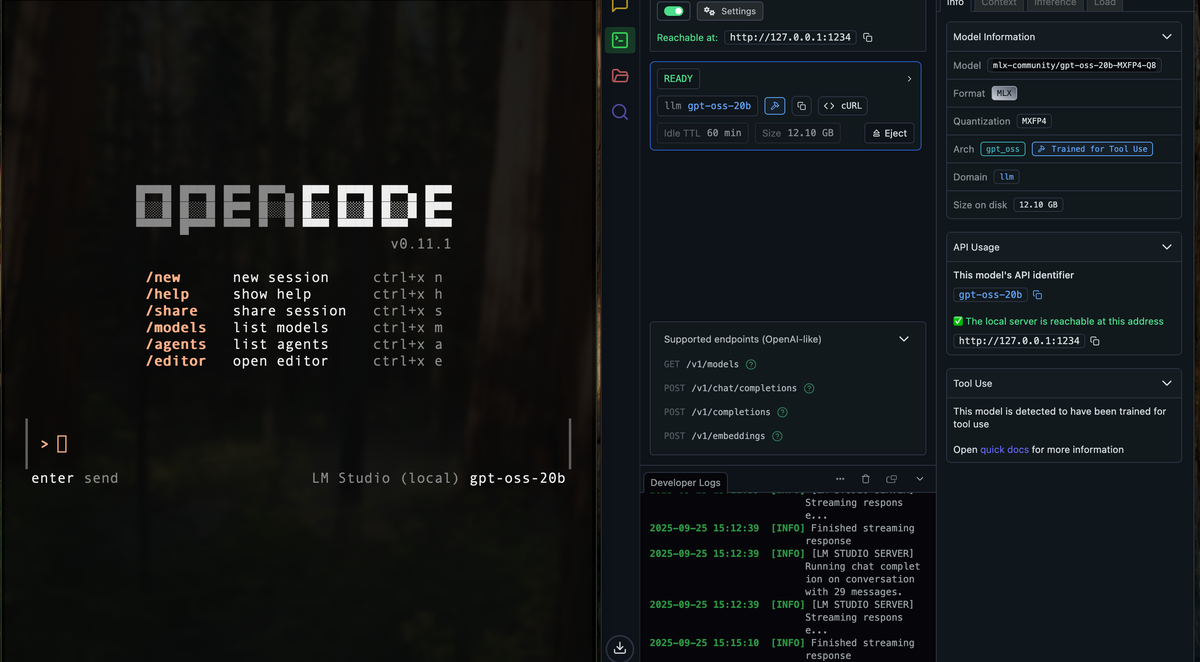
I wanted a Claude Code–style coding buddy that runs 100% locally on my MacBook Pro: no API keys, no cloud costs, and fast on Apple Silicon. After a short detour with MLX Knife, the winning combo was:
- LM Studio for a local, OpenAI-compatible API server
- GPT-OSS-20B (MXFP4) as the model
- OpenCode as the terminal coding agent
Below is exactly what I ran and clicked, plus the one config file that makes it all gel.
tl;dr (copy-paste)
# 1) Install LM Studio (GUI + local API server)
brew install --cask lm-studio
# 2) (Optional) launch LM Studio from terminal
open -a "LM Studio"
# 👉 In LM Studio UI:
# - Start the Local Server (Runtimes → Developer) until it says:
# Reachable at http://127.0.0.1:1234
# - Load the model: gpt-oss-20b (MLX / MXFP4)
# - Turn the Context Length slider way up (OpenCode uses long prompts)
# 3) Quick API smoke test (expects LM Studio at :1234)
curl http://127.0.0.1:1234/v1/models
curl -s -X POST "http://127.0.0.1:1234/v1/chat/completions" \
-H "Content-Type: application/json" -H "Authorization: Bearer EMPTY" \
-d '{
"model": "gpt-oss-20b",
"messages": [{"role":"user","content":"Say hi in one sentence."}]
}' | jq .
# 4) Install OpenCode (terminal coding agent)
brew install sst/tap/opencode
# 5) Create OpenCode config (provider → LM Studio, model → gpt-oss-20b)
mkdir -p ./.opencode
cat > ./.opencode/opencode.json <<'JSON'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"lmstudio": {
"npm": "@ai-sdk/openai-compatible",
"name": "LM Studio (local)",
"options": {
"baseURL": "http://127.0.0.1:1234/v1",
"apiKey": "EMPTY"
},
"models": {
"gpt-oss-20b": { "name": "gpt-oss-20b" }
}
}
},
"model": "lmstudio/gpt-oss-20b"
}
JSON
# 6) Run it 🚀
opencode
The longer story
I set out to recreate the “talk to your editor” workflow, but fully local. I first tried MLX Knife to host an OpenAI-compatible server on http://127.0.0.1:8000/v1. It did spin up—and even had a tiny simple_chat.html—but OpenCode needed a few API behaviors the server didn’t fully cover. Specifically, I ran into OpenAI-compat mismatches (e.g., JSON field naming) and a missing embeddings endpoint, which some clients expect. Those gaps are tracked in the project’s issues, so it may work out of the box later; it just didn’t for my setup today. (GitHub)
So I pivoted to LM Studio, which exposes the familiar OpenAI-like endpoints (/v1/models, /v1/chat/completions, /v1/completions, /v1/embeddings) on a local server—by default reachable at http://127.0.0.1:1234/v1. That instantly clicked with OpenCode. (LM Studio)
step-by-step (with a couple of gotchas I hit)
1) install LM Studio
brew install --cask lm-studio
open -a "LM Studio"
2) start the local server + load the model
In LM Studio:
- Go to Runtimes → Developer and toggle the server to Running. You should see Reachable at
http://127.0.0.1:1234and a list of supported OpenAI-like endpoints. (LM Studio) - Load
gpt-oss-20b(your screenshots show the MLX format with MXFP4 quantization). - Important: drag the Context Length slider way up (your pic showed support up to
131072). OpenCode sends longer task prompts than a normal chat; with a tiny context window, tools won’t run well.

3) smoke test the API
curl http://127.0.0.1:1234/v1/models
curl -s -X POST "http://127.0.0.1:1234/v1/chat/completions" \
-H "Content-Type: application/json" -H "Authorization: Bearer EMPTY" \
-d '{
"model": "gpt-oss-20b",
"messages": [{"role":"user","content":"Quick smoke test."}]
}' | jq .
LM Studio speaks OpenAI-compatible JSON on those endpoints, so this should stream back a response. (LM Studio)
4) install OpenCode
brew install sst/tap/opencode
(Official install paths—brew and script—are in their docs/readme.) (opencode.ai)
5) point OpenCode at LM Studio (one config file)
I used a provider pointing to LM Studio’s baseURL. The config below is exactly what I run:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"lmstudio": {
"npm": "@ai-sdk/openai-compatible",
"name": "LM Studio (local)",
"options": { "baseURL": "http://127.0.0.1:1234/v1" },
"models": { "gpt-oss-20b": { "name": "gpt-oss-20b" } }
}
},
"model": "lmstudio/gpt-oss-20b"
}
Docs show exactly this pattern for OpenAI-compatible providers (custom baseURL, map of models). (opencode.ai)
Then put it in ~/.opencode/opencode.json
Once OpenCode boots, I select the model and start giving it real dev work (“set up a Go REST handler + Makefile and explain each change”), and it runs entirely through LM Studio locally.
what it’s like in practice
With LM Studio + OpenCode, the workflow feels like Claude Code in my terminal—edits, diffs, planning, and “do-this-then-that” loops—entirely offline. On my MacBook Pro, GPT-OSS-20B (MXFP4) is a sweet spot: strong reasoning, reasonable VRAM/RAM footprint, and it keeps up with iterative coding.
Final Note
Here are the reasons why I choose the tech stack:
- reasoning capability
GPT-OSS-20B is a mixture-of-experts (MoE) model. Even though it has 20B parameters in total, only a subset of experts activate per request. This design gives it strong reasoning skills without needing to run all 20B parameters at once. - runtime memory efficiency
Because MoE only “turns on” part of the model each step, the effective compute is closer to ~3–4B active parameters. That keeps memory usage low enough to run smoothly on a MacBook Pro instead of a datacenter GPU. - mlx optimization
The model comes in MLX format, which is Apple’s deep learning framework optimized for M-series chips. MLX takes advantage of Apple Silicon’s GPU and memory architecture, so inference runs faster and more efficiently compared to generic formats. - quantization (MXFP4)
The weights are stored in MXFP4, a 4-bit floating-point quantization scheme supported natively in MLX. This drastically reduces the model’s footprint on disk and in RAM, while still preserving reasoning quality. In practice, this means GPT-OSS-20B (MXFP4) fits comfortably in ~12 GB, perfect for laptop use.
I suppose LM Studio could easily be swapped for something else that support MLX optimization. And open code can be swapped for something like goose too. Try and play with your favorite tool! The horizon for edge AI is getting closer and closer.
references
- LM Studio OpenAI-like endpoints:
/v1/models,/v1/chat/completions,/v1/completions,/v1/embeddings. (LM Studio) - LM Studio via Homebrew cask (install line). (Homebrew Formulae)
- OpenCode providers/config (custom OpenAI-compatible baseURL). (opencode.ai)
- MLX Knife issues illustrating why I switched (format mismatch & missing embeddings). (GitHub)