Vibe出我的屬靈導師:(嘗試)讓 AI 不再膚淺
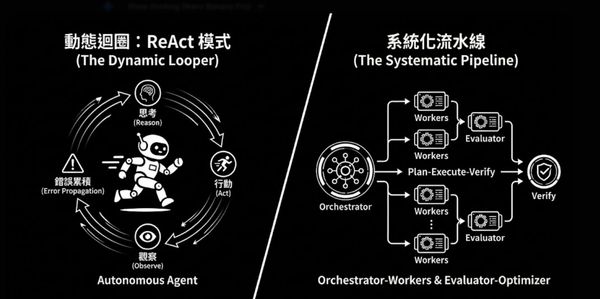
我們厭倦了 AI 缺乏溫度的「心靈雞湯」。本文詳述如何利用 RAG 將屬靈經典注入 Chroma 雲端 Collection。後端採用 FastAPI 伺服器,透過提示工程實現 Persona 分離。利用 LM Studio 搭配 MLX FP4 量化模型在 Mac 本機運行,兼顧隱私與低延遲。

我依賴 AI 來寫程式碼、處理資料、解決專業領域的難題。它快、精準、邏輯清晰,是個優秀的「資訊處理器」。但是,當我試著在心靈深處尋求對話、指引或一些詩意的靈感時,AI 的回答總是透著一股難以言喻的「味道」——那種制式化、缺乏溫度的「AI 味」。
或許是因為在大型語言模型的強化學習 (RL) 或微調過程中,設計者主要將模型的優化目標聚焦於事實準確性、邏輯連貫性與安全合規上。然而,人類靈魂深層的、非結構性的、詩意的需求,卻很少成為 AI 被深度優化的目標。
幸好,人類歷史上有無數偉大的屬靈導師,他們的作品早已沉澱了千年智慧。既然 AI 缺乏深沉的靈魂維度,我們何不將這些屬靈經典作為 AI 的「記憶」?我決定做一個實驗:透過 RAG (Retrieval-Augmented Generation) 技術,將畢德生(Eugene Peterson) 的牧者智慧和坎培斯 (Thomas à Kempis) 的修院語氣等人的著作注入 AI 的知識庫。
以下就是我一步步用「提示(prompt)」打造我的心靈導師的過程。
從 PDF 到章節:讓經典被「讀懂」
我的第一個挑戰是讓這些經典「讀得懂」。這些智慧都被鎖在一整份龐大的 PDF 檔案裡。我想要的不是把整本書隨機切成幾百個碎片(那會失去語境,像完整的故事被斷章取義),而是要尊重作者,按「章節」來理解。畢竟,一個章節本身就是一個完整的思緒單元。
我寫了幾個prompt,幫我把 PDF 檔案逐章逐節地轉換成 Markdown,並要求它務必保留原文的語氣,一個字都不許亂改。拿到初稿後,我又讓 AI 幫我按章切分檔案,確保每一個檔案都是一個獨立的、帶有語義完整性的「記憶」單元。這是 RAG 系統穩定的基礎。
建立心靈圖書館:Chroma 與索引卡
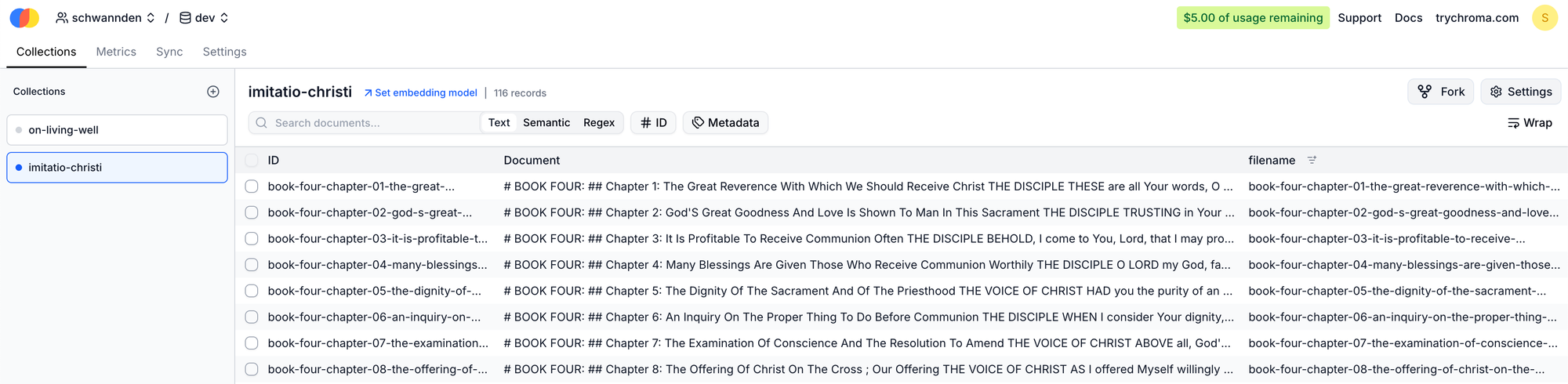
接下來,我需要一個「圖書館」來存放這些珍貴的章節。我選擇了 Chroma 雲端服務,主要是看中它的免費額度與免維護特性(不用自己維護database)。
我又請 AI 幫我生成了一個簡單的 Python 腳本。這個腳本走訪每個章節檔案,並在寫入 Chroma collection 時,一併附上「書名」和「章名」這兩個關鍵的「標籤」(Metadata)。這就像給每一段智慧語錄都貼上了一張清晰的索引卡,確保未來檢索時能精確找到出處。
給 AI 戴上導師的帽子
參考指令
Build a FastAPI RAG chatbot that serves a small Tailwind frontend at /chat. Use Python 3.11, FastAPI, httpx, ChromaDB (cloud client) for embeddings retrieval, and LM
Studio’s OpenAI-compatible local API for generation. Requirements:
- Env vars: CHROMA_API_KEY, CHROMA_TENANT, CHROMA_DATABASE (default “dev”), LM_STUDIO_BASE_URL (default http://host.docker.internal:1234), LM_STUDIO_CHAT_MODEL (default openai/gpt-oss-20b).
- Retrieval: top_k with default 7, cap 8; allocate fairly across collections. Max context per doc 1200 chars. Response length presets: short/medium/long with approximate char targets.
- Chat endpoint POST /chat: accepts messages [{role, content}], top_k, collections, response_length; returns reply plus sources (collection, label, filename, distance).
現在,我的「圖書館」有了,就需要一位「館長」來處理請求。我再次使用提示,請 AI 幫我搭建一個 FastAPI 伺服器作為後端。這位「館長」的任務很明確:
- 根據使用者選擇的導師,到圖書館裡檢索出最相似的幾段經文。
- 把這些經文優雅地彙整成一個「上下文」。
- 最關鍵的是:它必須在這個上下文中,要求回應模型使用「屬靈導師的口吻」,溫柔、沉穩,並明確標註來源章節。
- 最後一條戒律:如果圖書館裡找不到相關內容,它絕對不能亂編,必須坦誠告知。
我就是在 AI 給出的骨架上,補足了錯誤處理和細節配置,讓它能順利將檢索到的智慧,送往我的本機推理模型進行「解讀」。

本機模型
我把語言模型跑在我自己的 Mac 上,搭配 LM Studio 與 MLX FP4 量化模型。
前端:
為了簡單的自己實驗整個Rag建置,我沒有使用既有的聊天框架,想看看 Codex 能不能理解我的概念,幫我兜出整個前端。看起來完全難不倒 Codex: https://github.com/schwannden/spiritual-director-chat
實驗:人格分離,讓導師的聲音更純淨
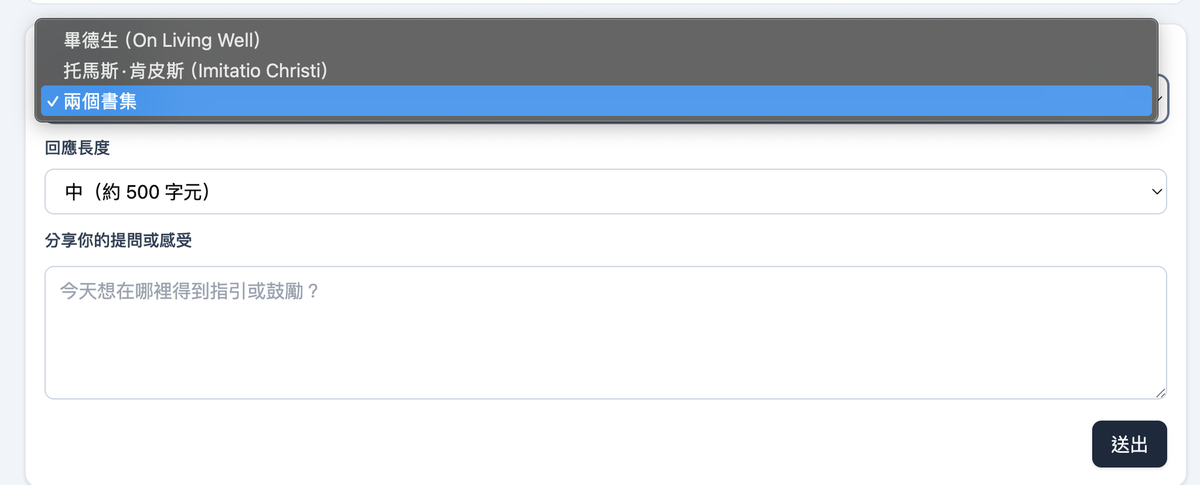
玩了一陣子後,我發現自己貪心了。我不想只有一位導師,我想能自由切換「畢德生的牧者語氣」和「坎培斯的修院語氣」,讓我可以看看中世紀的智慧跟當代牧者的差異。
於是我回頭修改提示,加入了「人格 (Persona) 分離」的設計。我讓前端增加了一個下拉選單,後端則會根據我的選擇,只去查對應的資料庫,或是將兩本書的上下文合併。更精確的系統提示,確保模型在回應時能保持選定導師獨有的語氣,避免兩位聖賢的聲音「混音」,讓指引更為純淨清晰。
參考指令
Evolve the existing RAG chatbot to support two distinct personas tied to the collections. Requirements:
- Collections stay “on-living-well” and “imitatio-christi”, but add persona-aware voices.
- on-living-well → Eugene Peterson: warm, pastoral, conversational.
- imitatio-christi → Thomas à Kempis: reflective, devotional, humble.
- both → blend the two voices naturally.
- Update the system prompt generation so the tone changes based on selected collections; keep the default to on-living-well when none provided.
- Keep retrieval/top_k logic intact; if “both” is requested, spread top_k across collections as before.
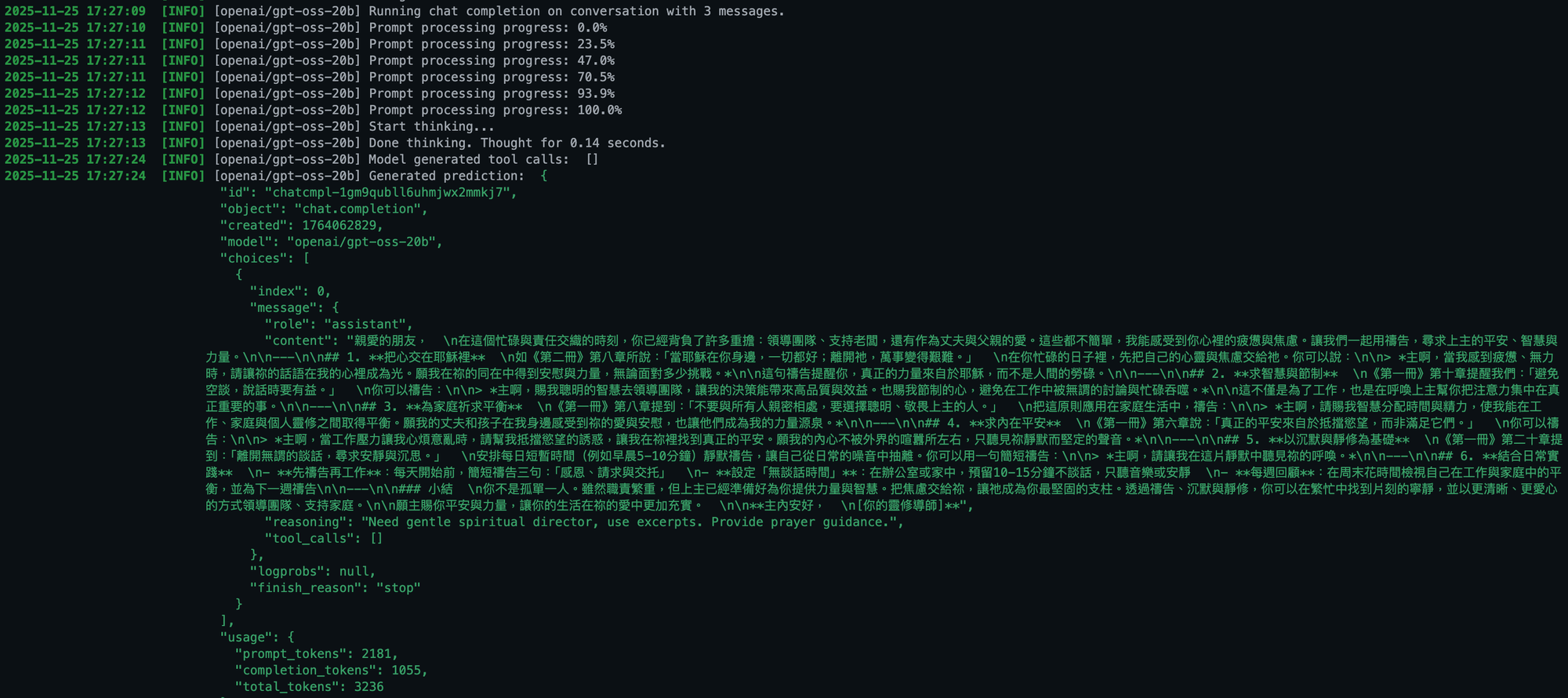
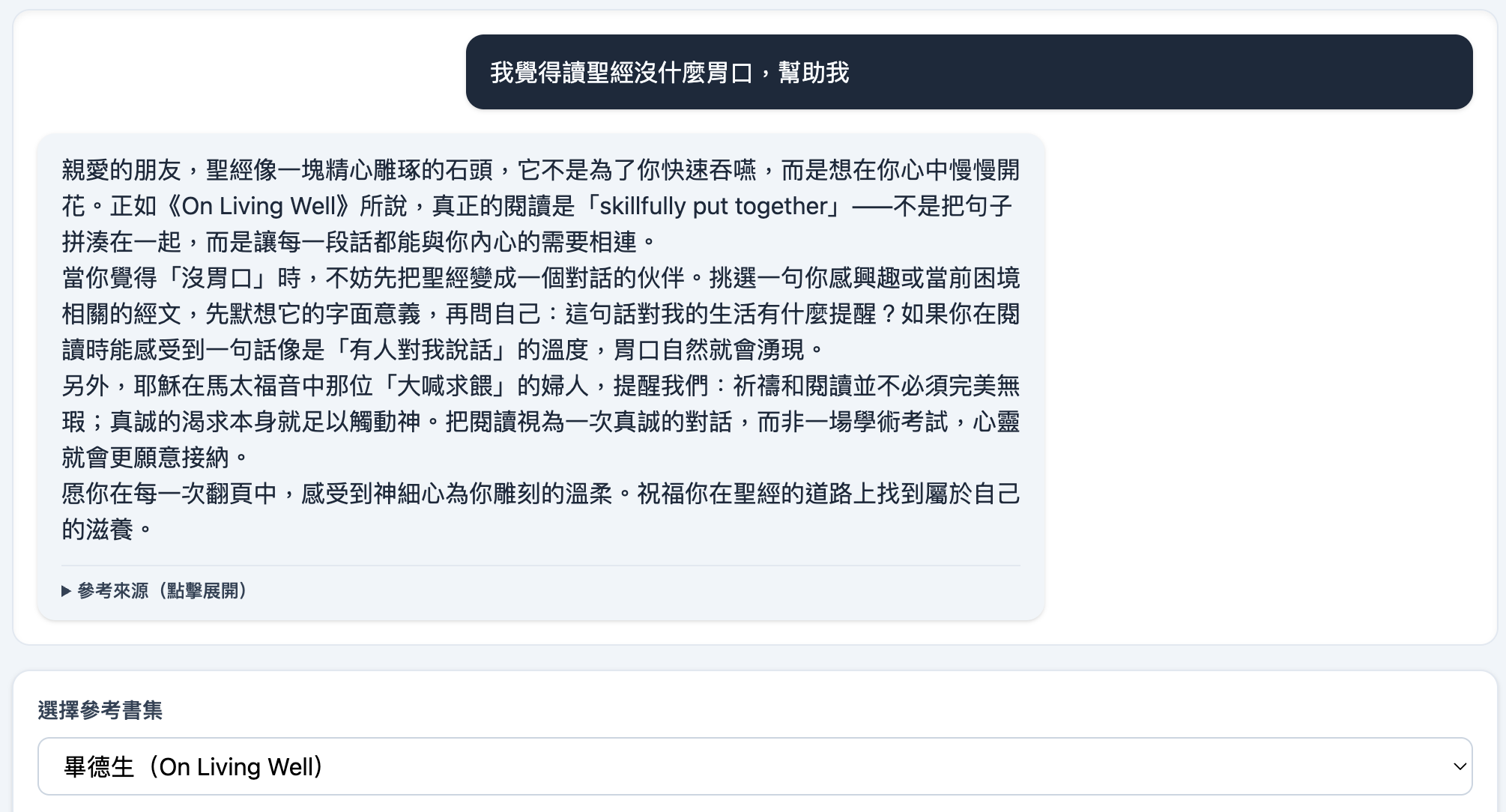
拿同一個問題,選擇不同的屬靈經典作為依據回答,AI確實可以開始模仿我們要他成為的人。
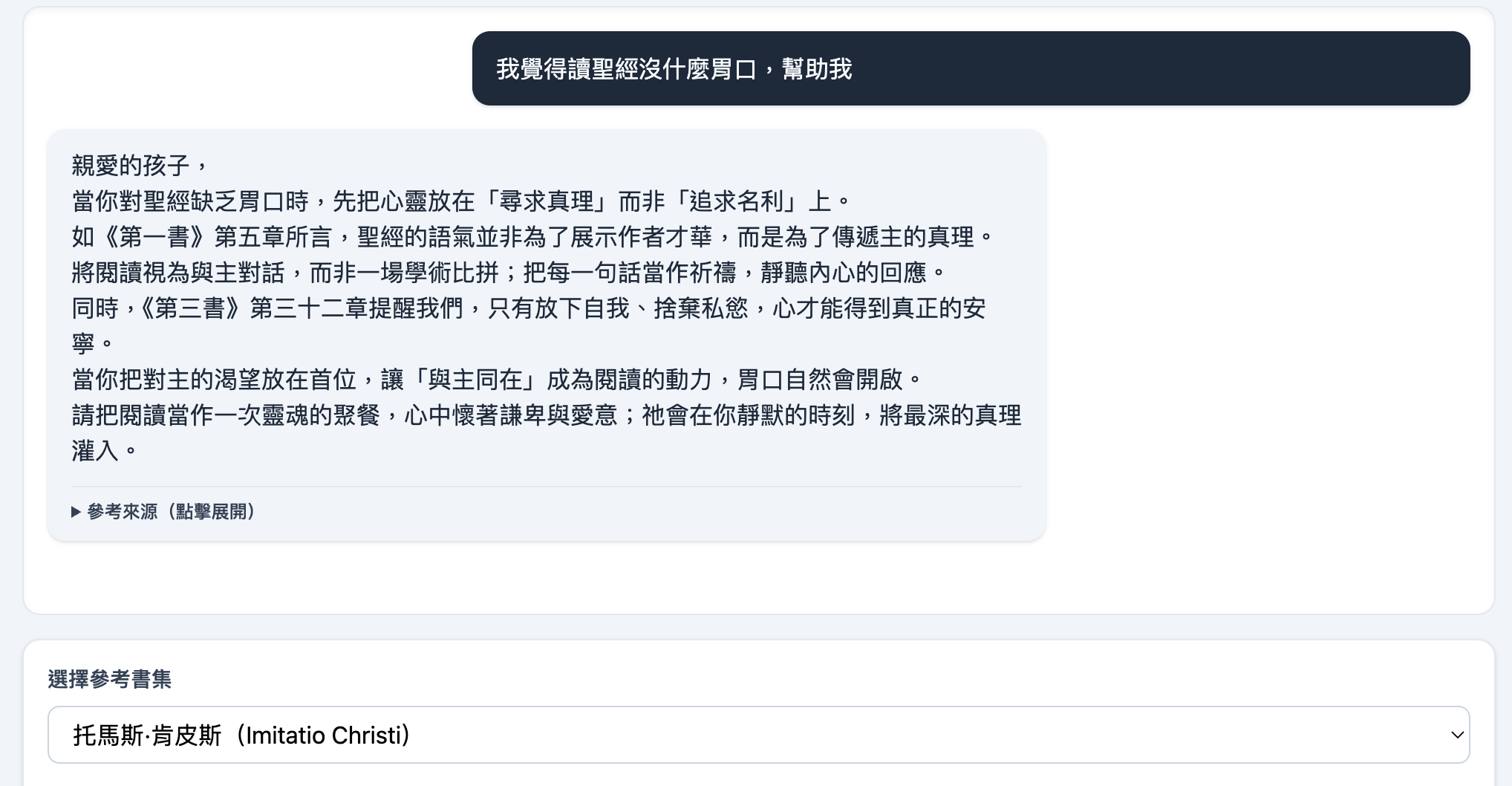
在這個小小的實驗室裡,我看到了不同世代屬靈智慧的差異:
- 當我選中畢德生的近代屬靈智慧時,導師的回應帶著一種溫柔的基調,教我們溫柔地對待自己,看重平凡與日常中的恩典。
- 當我切換到坎培斯的中世紀修院智慧時,回應則轉為一種更嚴謹、更克制的語氣,提醒我們要忘我、要捨己,將目光專注於更高遠的目標。
最終的反思:有限的科技,無限的生命
這個 RAG 實驗雖然成功地讓 AI 穿上了「屬靈導師」的外衣,但它也讓我更清楚地意識到:AI 在心靈領域能提供的幫助,終究是極其有限的。說到底,這次的嘗試,本質上只是想看看 AI 能否至少精確地模仿我喜歡的作者語氣,同時順便測試一些好用且免費的開源工具(如 Chroma、LM Studio)。
真正的屬靈指引,其困難度遠超於此。它沒有固定的 SOP 或一套通用的語氣。面對同一個問題,一位屬靈導師必須深知對方的光景與時代盲點,才能準確回應:究竟是該挑戰、安慰、責備,還是僅僅是單純地陪伴、禱告與聆聽?這一切,都需要建立在愛的關係、順服的關係、長時間累積的理解,以及在關係中不斷加深的認識。
因此,這個系統的最佳定位,是作為一本經典導讀工具,而非一位真正的導師。它為我們打開了一扇門,讓我們更貼近那些偉大靈魂的文字,但通往心靈深處的道路,依舊需要我們自己投入真實的生命與關係。